0. Chat Bots学习资料
Contents
Chat Bots学习资料
智能问答文献调研
1. 基于开源引擎的智能问答系统设计与实现,李一飞,华中科技大学,2017
主要功能模块划分如下:
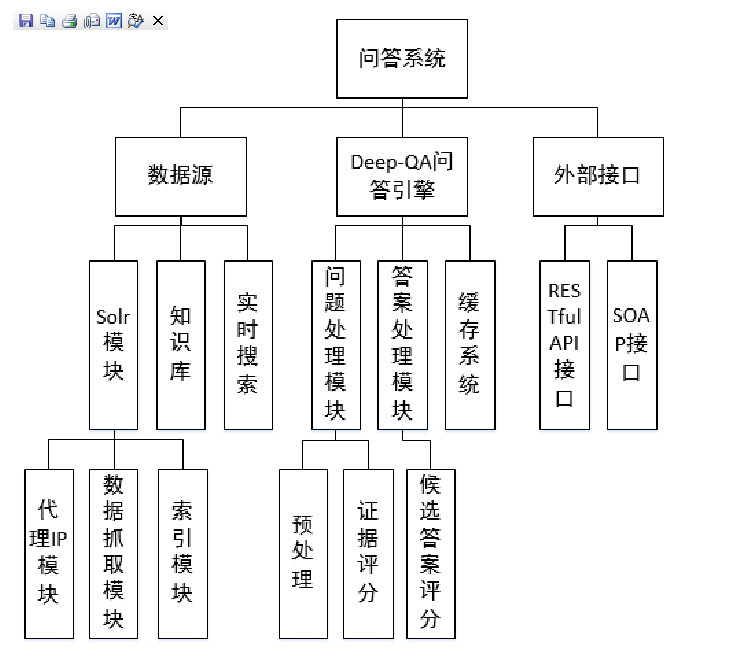
涉及到的程序包有:
- Lucene: 全文索引引擎架构
- Jsoup:HTML文档解析器
- Ansj:中文分词
- Jackson:Json解析器
- Stanford-corenlp:斯坦福大学自然语言研究小组的研究产物,自然语言集合处理工具
- Solrj:Solr的java客户端
- Hanlp:汉语言处理包
- Hibernate:ORM工具
- c3p0:数据库连接池
- QuestionAnsweringSystem:开源项目
2. 面向医疗健康领域的智能问答系统的设计与实现,王蕾,北京邮电大学,2018
本课题的研究内容包括分析高血压相关医疗知识、建立高血压知识库并为之设计高效的访问机制、推理规则,系统涉及的技术包括高血压知识的获取与表达、知识推理、知识检索、知识问答等。
采用的方式是:利用相关医疗知识构建知识图谱以及知识模型。当系统接收一个句子是,通过句子分析对用户的话语进行理解,然后得到用户的意图,根据知识表示进行相应的知识搜索,通过知识搜索的方法查找答案,得到的是以用户真实需求为基础的答案。
OWL语言构建知识库,SWRL语言构建推理规则,Jena进行规则推理,RDF资源描述框架,Protege工具构建本体。
通用知识图谱:CN-DBpedia,PKU-PIE,Zhishi.me。
国外典型的医疗领域知识图谱搜索引擎有WebMd,Healthline等。
知识库问答的简要流程:
高血压应该挂哪个科室? -> 语义解析 -> 语义表示 -> 语义匹配、推理、查询 <-> 知识库。
分词库构造,以第三章建立的本体为数据源,提取所有的专业名词词汇,再按照本小节选择的结巴词库组成总和词库。
3. 基于深度学习的智能问答技术研究,陈柏龄,广西大学,2018
本文首先对所用到的深度学习技术进行分析研究。引入Bi-GRU进行语义编码,得到较完整的语义理解向量。根据注意力思想,构建语句级别的多步注意力机制,提升神经网络模型在获取答案相关的本文信息向量的准确性。随后便是将两者结合到一起。
Word2vec是google开源实现了CBOW和Skip-gram模型的词向量训练框架,可以从文本语料库中高效地学习独立的词嵌入。
卷积神经网络也常被用于自然语言处理,它的模型被证明可以有效的处理一些自然语言处理的任务,如句子建模(A Convolutional Neural Network for Modelling Sentences)、词语分类(Convolutional Neural Networks for Sentence Classification)、语句预测、语义分析(A deep architecture for semantic parsing)、搜索结果提取和其他传统的NLP任务(Natural Language processing (almost) from scratch)。
例子中采用的是英文数据集。
4. 基于注意力机制的多轮视频问答,姜兴华,浙江大学,2018
提出新的多轮视屏问答模型。先通过层级对话上下文序列进行建模,提出了关注历史对话序列的问题理解嵌入表示结构。然后,开发了多通道时空感知网络,用于学习动态视屏内容和上下文感知问题嵌入的联合表示。最后,采用多层次多步推理注意力网络完成视屏问答。
他人的相关研究:
- Sequential match network: A new architecture for multi-turn response selection in retrieval-based chatbots.
- Hierarchical recurrent attention network for response generation.
5. Sequential Attention-based Network for Noetic End-to-End Response Selection
1 2 3 4 5 6 7 8@article{DBLP:journals/corr/abs-1901-02609, author = {Chen, Qian and Wang, Wen}, title = {Sequential Attention-based Network for Noetic End-to-End Response Selection}, journal = {CoRR}, volume = {abs/1901.02609}, year = {2019}, url = {http://arxiv.org/abs/1901.02609}, }
The typical approaches for multi-turn response selection mainly consist of sequence-based methods and hierarchy-based methods.
6. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems
Lowe R, Pow N, Serban I V, et al. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems[J]. annual meeting of the special interest group on discourse and dialogue, 2015: 285-294.
引入了语料库,并使用两种神经网络架构利用该数据集进行了学习。包括simple frequency-inverse document frequency (TF-IDF) approach, RNN, LSTM.
数据集的位置:https://github.com/rkadlec/ubuntu-ranking-dataset-creator
实现代码例子:https://github.com/stupidgrass/ubottu (fork from https://github.com/npow/ubottu)
创建语料库
需要考虑的场景如下:
- 一句话的开头和结尾可能有对话接受者的名字
- 最早被第一个回复者at到的人,可能是初始问题提出的人
- 没有发现初始提问者,或第一个回复者的对话都被删除
- 长于五轮对话中,有80%的对话来自同一个人,那么这组对话被删除
- 不考虑比3轮对话更短的情况
- 针对同一个提问者,多个回复者的情况,将每一个提问-回复对都作为单独的对话
TF-IDF
term frequency-inverse document frequency. 词频重要性分析。term-frequency表示一个单词在上下文中出现的次数。inverse document frequency表示一个单词在预料其他地方出现的可能。最后计算公式为:
$$tfidf(w,d,D)=f(w,d)log\frac{N}{|{d\in D:w\in d}|}$$
其中$f(w,d)$表示单词w在上下文d中出现的次数,N是总的对话数,分母表示单词w在出现在所有对话中的对话数。
相关介绍可以参见:https://www.cnblogs.com/en-heng/p/5848553.html
RNN
在这篇文章的基础上构建"Open question answering with weakly supervised embedding models”
仅考虑下面的参数:
|
|
LSTM
将RNN替换成LSTM进行实现。相关理解主要通过阅读源代码实现。
仅考虑下面的参数:
|
|
7. Deep Learning Based Chatbot Models
Csaky, Richard. (2017). Deep Learning Based Chatbot Models. 10.13140/RG.2.2.21857.40801.
博客文章调研
-
该博客的代码实现直接间接使用了tensorflow中自带的seq2seq模块。
-
Deep Learning for Chatbots, Part 2 – Implementing a Retrieval-Based Model in Tensorflow
-
How I Used Deep Learning To Train A Chatbot To Talk Like Me (Sorta)
github实现调研
搜索如下:https://github.com/search?o=desc&q=chatbot&s=stars&type=Repositories,举例如下:
Author grassofsky
LastMod 2019-08-07