rasa blog - integrate response retrieval models in assistants built with Rasa (翻译)
Contents
rasa blog - integrate response retrieval models in assistants built with Rasa (翻译)
在这篇文章中,我们会介绍rasa新增的(试用阶段)retrieval-based response selection功能。Rasa1.3.0引入了Retrieval Action和ResponseSelector NLU组件。该功能使得对于 small talk, chitchat, FAQ 相关问题的处理变得更加简洁。简单的讲,本文主要覆盖了三个主要的思想:
- 使用Rasa能够更加方便的处理单轮对话
- 将单轮对话定义到训练数据中,而不是简单的定义到domain文件中
- 创建模型用于单轮交互的回复选择
Retrieval Actions
Retrieval actions被用来处理FAQs,chitchat等单轮交互的问题。这里的单轮交互,意味着助手总是以相同的方式进行回复,不用在意之前的交互。具体示例如下:
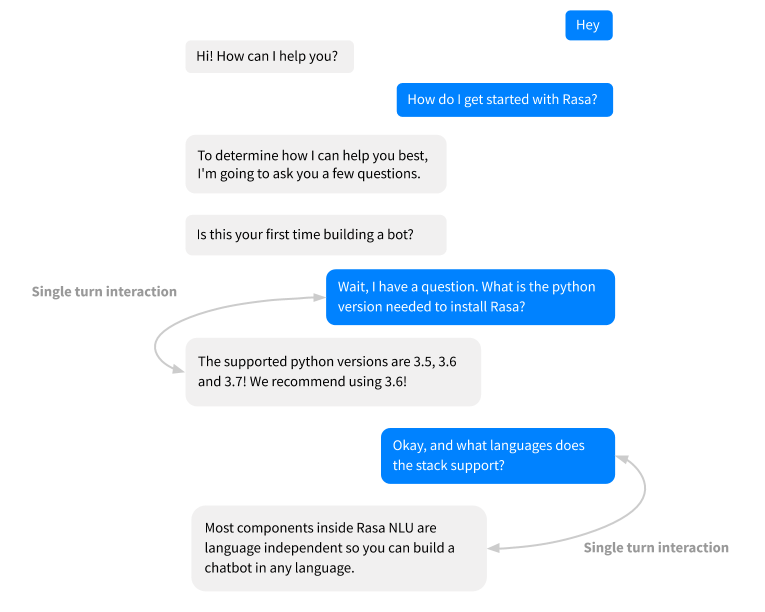
当用户寻问Sara(我们的demo机器人)推荐的python版本的时候,Sara应该总是回答相同的答案。并且和之前的对话不相关。
在这个功能提出来之前,我们需要针对每个FAQ问题创建一个story,看上去是这样子的:
|
|
如果使用retrieval action,你只需要一个story,
|
|
那么有什么不同呢?所有FAQ相关的意图都被合并成单个retrieval intent,并且响应也成为了单个action respond_faq。这使得能够很容易的将所有的FAQ视为相同的方式,当做与具体意图无关的retrieval action。
由于此处的意图和之前的消息没有关系,我们不需要一个复杂的pjolicy来预测相关的retrieval action。但是,由于只有一个retrieval action,我们需要构建一个机器学习模型来从action的一系列的候选选项中挑选出合适的回复。我们是怎么实现的呢?
Superivised Response Selector
我们介绍一个NLU中新的组件,RespjonseSelector。这个组件的工作如下:
- 收集每个用户消息和候选响应的词袋特征
- 将词袋特征输入到稠密连接层,计算每个的嵌入向量
- 使用相似度计算公式计算用户输入消息和候选响应嵌入向量之间的相似度
- 是正确的问答对之间的相似度最大化,错配的问答对之间的相似度最小化。这是训练模型过程中由最优化函数实现
- 获取用户输入和所有候选响应之间的相似度,挑选出相似度最高的作为针对用户输入的响应
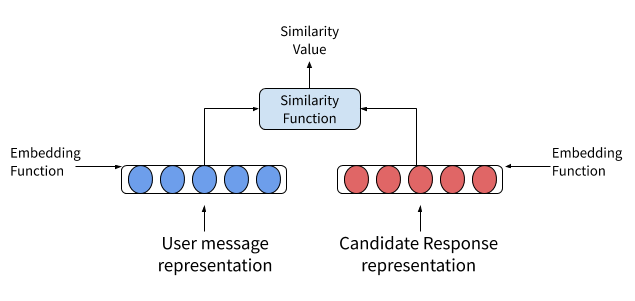
这个看上去和EmbeddingIntentClassifier的工作方式很相似,它们之间的主要不同点是意图文字被响应的实际文字给取代了。
这个组件需要放在tokenizer,featurizer,和intent classifier之后。如:
|
|
Training Data
让我们来看一下训练数据。
Retrieval Intents
我们的ask_faq意图NLU示例如下:
|
|
这里有两个相关的意图,ask_faq/python_version和ask_faq/languages。意图分类器将上面的意图合并成为retrieval意图,ask_faq。只有ResponseSelector关心ask_faq/python_version和ask_faq/languages的不同。
Response Phrases
现在实际的响应文本是训练数据的一部分了,因此不再出现在你的domain文件中。这是标准的机器响应和retrieval actions很重要的一个不通电。由于我们直接通过用户的输入消息选择回复,响应选择是朝着端到端chatbot训练迈出的一步。因此,我们使用类似于end-to-end evaluation中的故事格式:
|
|
这里强制将这些回复写入到单个独立的文件中(你可以命名为responses.md,或其他),并且在这个文件中不能有其他的NLU训练数据。这个独立的文件还是可以放在相同的文件夹下面。
Retrieval actions
rasa使用命名约定来匹配检索意图的名称,如ask_faq匹配到对应的action,名字为repond_ask_faq。repond_前缀用来定义retrieval action。你应该在你的domain文件中添加retrieval actions。这里有两个途径用来触发这些actions:
1- 如果你需要在监听下一个用户输入的时候总是响应respond,可以使用MappingPolicy,将retrieval意图与actions进行关联,如下:
|
|
2- 如果你定义随后的actions(比如,询问用户是否需要继续),在stories中像其他action一样包含其他action。
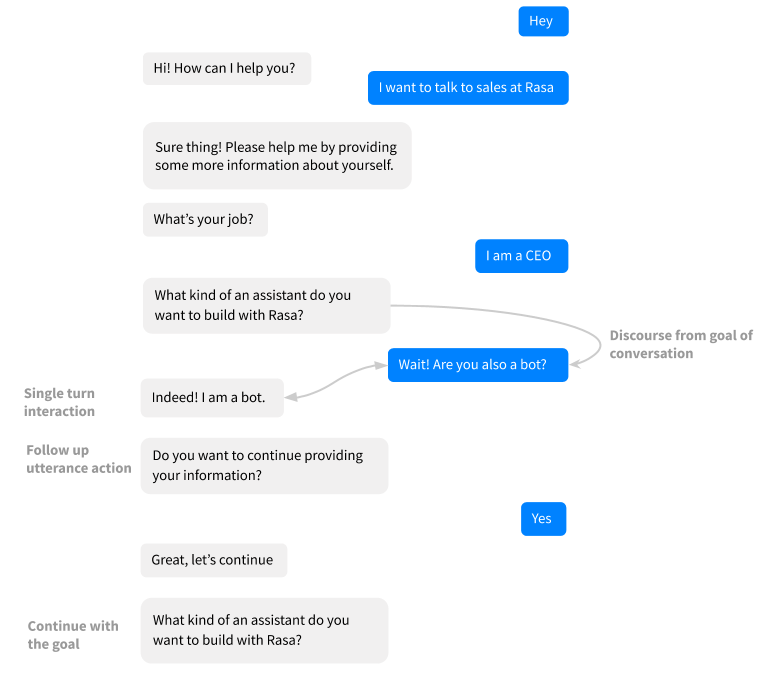
story类似如下:
|
|
总的来说,我们试着在两个主要因素上简化训练数据格式:
- 开发人员经验:训练数据格式对于开发人员尽可能的直观,不能和现有的训练数据格式有很大的区别。
- 逻辑意义:训练数据的所有元素都应该符合Rasa内部元素的现有逻辑结构——例如,训练数据不应该在域文件中。
Playing a bit more with Response Selector
rasa允许您有多个检索意图和相应的多个检索操作作为助手的一部分。在这种情况下,您有两个选项:
1- 您可以构建一个共享响应选择器模型,该模型将在您的助手的所有检索意图中对用户话语和响应话语对进行培训。在这种情况下,不需要在响应选择器的配置中定义检索意图参数。
2- 可以为每个检索意图构建特定的响应选择器模型每一个模型都将训练用户话语和根据检索意图分组的响应话语对。因此,NLU配置中的响应选择器组件的数量应与训练数据中的检索意图的数量相同为此,请使用每个响应选择器组件配置中的retrieval_intent参数定义相应的检索意图:
|
|
选择特例的选择模型,还是选择共享,这是受用户使用情况驱动的。如果对话中的特别的retrieval intent是领域相关的,如,FAQ相关的问题,这样和chitchat或greeting意图进行共享,就不太合适了。使用各自独立的模型,可以对参数进行定制。比如,当使用平衡批处理作为批处理策略时,如果某些常见问题的数据比其他常见问题的数据多得多,则培训可能会有所改进。
我们希望开发人员能够灵活的尝试和测试对他们最有效的方法。在我们的实验中,为所有检索意图构建一个共享响应选择器模型,与为每个检索意图创建单独的模型相比,得到了相似的结果。如果您观察到不同的结果,请在论坛上与我们分享(forum.)。
Why is the feature experimental?
随着response selector和retrieval actions的引入,我们提出了一种处理单轮交互的新方法。训练数据格式并不完全支持端到端训练,但仍然是朝着这个方向迈出的一步。此外,响应选择器组件位于Rasa NLU和Core的交叉点尽管我们相信端到端的培训是一个令人兴奋的领域,但我们希望在进一步深入之前,从社区获得关于总体开发人员体验、模型性能和功能本身的足够反馈。因此,我们计划暂时保持这个特性的实验性这意味着可以根据我们收到的反馈更改或删除功能。
Conclusion
我们现在有了一种全新的方法来处理rasa助手中的单轮交互。此外,由于该功能是实验性的,我们鼓励您尝试并给出反馈如果你正在使用这个新组件构建机器人程序,或者只是测试它,请随时在论坛中发布它的运行情况。我们很高兴看到您用这个组件构建了哪些有趣的新用例!
Author grassofsky
LastMod 2019-12-21