rasa blog - 将Rasa和知识库进行集成
Contents
rasa blog - 将Rasa和知识库进行集成
Knowledge bases: Encode domain knowledge and resolve entities in Rasa
在这个教程中,你将会学到:
- 如何使用知识库,将你的助手带到下一个等级
- 知识库的类别,以及使用他们的时候需要解决那些挑战
- 如何在你的自定义actions中检索知识库
在单独的教程中(tutorial),你可以学会如何设置你的知识库。
Update:
我们在Rasa中添加了Knowledge Base Actions。请试用它。
Example
一个上下文助手需要一定知识库的基础上才能够走出反应,如,德国的任何一家银行,这就超出了预先定义的答案。为了满足用户的需求,需要特定的知识库。
让我们来看一个例子:
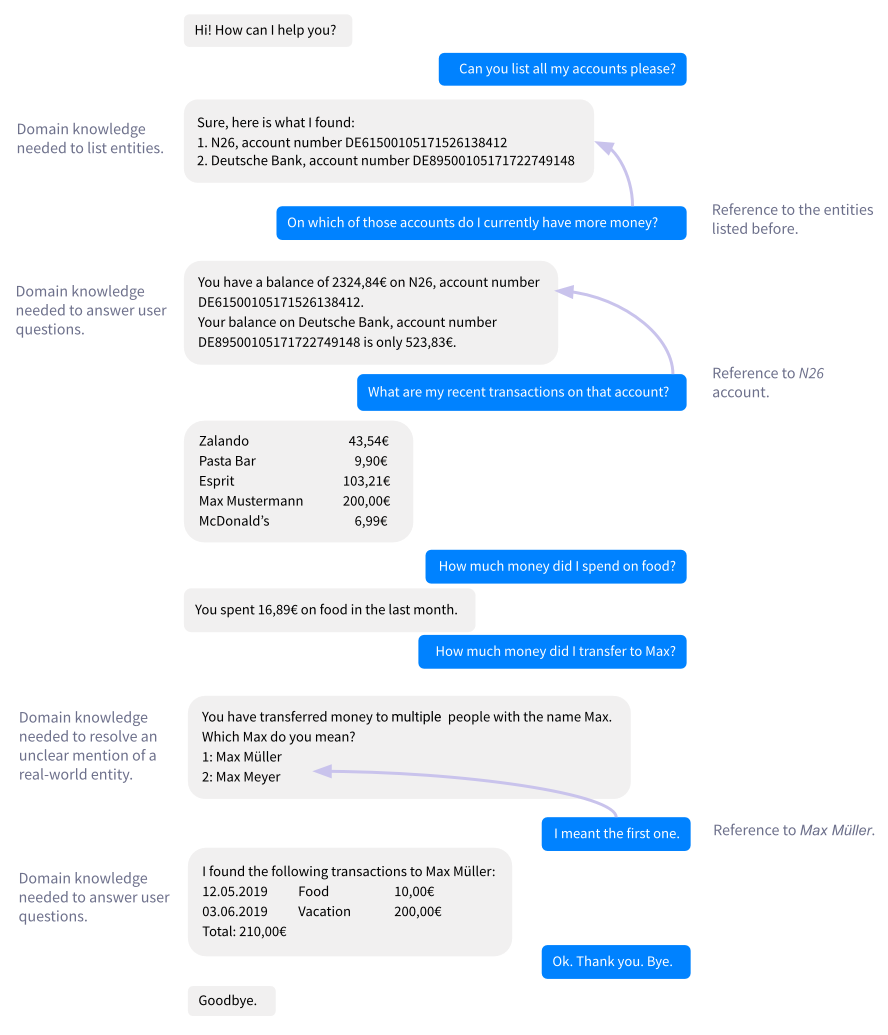
上面的很多的问题都需要领域的知识库才能够进行正确的回答。用户不单单想问关于某个实体的问题,他们还想要对实体进行比较,或者得到之前对话中更多的实体。对这些信息进行硬编码是没有帮助的。最近的交易会很快的变化,保持交易数据的实时性是很重要的。另外,你的bot需要能够处理类似于"that account"和"the first one"一类的实体,因此实体需要被识别出来,并在后面的对话中还会被使用到。
什么是知识库
知识库是用来存储复杂的数据结构。在你的知识库中存储的数据表示你的领域知识。比如,你可以存储一些银行的信息,或者存储银行和客户之间的关系。存在不同的技术帮助你将这些数据以有效的方式进行存储。为了学习知识库相关的更多的知识,可以查阅:“Set up a knowledge base to encode domain knowledge for Rasa”。
怎么在Rasa中使用知识库
在进入到细节之前,先看一下Rasa处理消息的常规流程。Rasa先解析消息,然后使用自定义的actions检索知识库,然后将得到的领域知识合并到回复中。
你可以在这里找到实现的例子,here. 这个banking bot能够针对你的账号相关的问题进行回答。
注意:每个bot是不同的,那么你的知识库很可能看上去也是不一样的,这个教程提供了例子,同时也鼓励你自己去实现。
让我们来看一下将知识库集成到Rasa需要的所有的步骤:
step 1: 构建知识库
首先,你需要设置你的知识库。在教程“Set up a knowledge base to encode domain knowledge for Rasa”中你可以学到如何一步一步的实现它。
step 2: 添加新的训练数据
为了理解客户实际的需求,你需要生成新的训练数据。需要记住一开始的示例对话:banking bot有四个意图,以及一些故事与领域知识相关。在下面的步骤中,你将会发现每个意图只有几个例子,仅仅是单个示例故事。你可以在这里发现完整的数据:here.
为了生成新的训练数据,你需要做三件事情:
Define new intents
你将会注意到banking bot的新意图是通用的。但是,实体是特定的。如果你把意图设定为通用,你的模型会非常的灵活,这样你也就没有必要针对你添加到知识库中的每一个新的实体创建新的意图。举个例子,如果你有一个通用的意图,叫做query_attribute,用来查找所有相关实体的属性,你只需要添加更多的示例到这个意图中。你并不需要增加你的故事。
让我们来看下,banking bot的新的意图:
query_entities
用户询问列出一些指定类型的实体。

query_attribute
用户想要知道某个实体更多的细节。他们询问那个实体特定的属性。
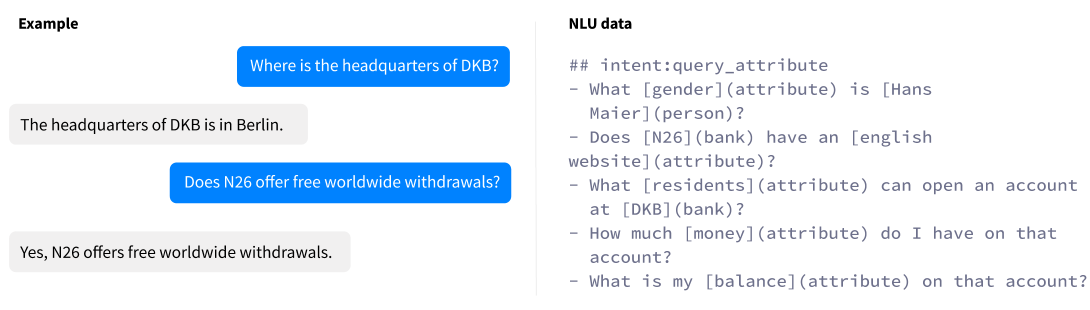
compare_entities
用户已经看到了实体列表。现在想要对这些实体的某个属性进行比较。

resolve_entity
用户可以选择实体选项,并且他们必须声明之前所指的实体。

定义新的故事
使用定义的意图,你可以将上面的对话转换成Rasa的故事。
|
|
如你所见,banking bot为每个意图定义了一个自定义操作,因为每个意图都要求你以不同的方式查询知识库。在步骤3中,你将定义这些自定义操作。一定要给你的故事增加一些不愉快的途径。你可以使用交互式学习 interactive learning或共享你的机器人share your bot功能来完成此操作。
更新你的domain文件
在定义了你的意图和故事之后,你需要在你的domain文件中添加你的意图,行为,和实体。见:here.
step 3: 添加自定义actions
为了检索你的知识库,你将使用自定义actions。自定义actions允许你以灵活的方式对用户的对话做出回复。如,你将看到如何写自定义action,action_query_attribute,以及如何处理某些边缘情况。
Write the custom action action_query_attribtue
为了写自定义action(custom action ),你需要集成Action类,并重写name和run函数。name方法需要返回action的名字。方法run包含具体的逻辑。因此,让我们从下面的框架开始:
|
|
因为banking bot使用图数据库来存储领域知识,banking bot将具体查找知识库的代码分装到了GraphDatabase类中,见:code。因此在run函数中,我们首先需要初始化GraphDatabase。
|
|
假设用户给出了如下的提问:

从图数据库中检索的实现类似如下:
|
|
如果你使用关系数据库,检索类似如下:
|
|
为了构建上面的query,你需要有如下内容:
- 感兴趣的实体(e.g. N26)
- 感兴趣的实体的类型(e.g. bank)
- 感兴趣的属性(e.g. headquarters)
- 实体类型的关键属性(e.g. name)
banking bot将前三项当做实体。通常情况下,banking bot使用slots,借用NER去识别他们。banking bot针对每个定义在知识库中的实体类型和属性都有slot。此外,还有其他的slots:
- listed_items: 实体的列表,如"
[N26, DKB, Deutsche Bank]” - entity_type: 用户想要问的实体类型,如"
bank” - mention: 之前提到的实体的引用,如"first”
- attribute: 用户需要查找的属性名字,如"headquarters”
通过这些检测到的意图和slots,你可以构建从知识库中检索想要信息的query。
让我们返回到这里例子中,如果你的NER正确的提取了这些实体,Rasa将在NLU pipeline或者之前对话的步骤中,设定entity type,attribute,bank的slots。在自定义action中,你可以通过get_slot获取这些值,如下:
|
|
我们假设所有的slot都被设置了。检索知识库还差一个东西:对应entity类型的关键属性,如(name)。为了获取这个关键属性,你需要在代码中以字典的形式定义数据库结构。所有的实体以及对应的属性都会被列出。此外,每个实体应该有个关键属性,和属性列表,可以用来输出这个实体。比如,bank的结构看上去是这样的:
|
|
使用这个字典,能够获取实体类型bank的key属性,现在具有了查询知识库的所有的信息:
|
|
graph_database.get_attribute_of()构建和执行了query,返回对应的result。最后需要将结果进行返回:
|
|
完整的action实现见:here.
解决同义词
看一下下面的问题:
- “Where is the main office of N26?”
- “Where can I find the HQ of DKB?”
NER将会检测到“HQ”和“main office”作为实体属性。为了从知识库中提取请求的knowledge,你需要解决“HQ”和“main office”是相同的属性,都是“headquarters”。为此,banking bot使用存储在知识库中的映射表。基本上,映射表只是一个映射,正如名称暗示的那样。因此,“HQ”被映射到“headquarters”。banking bot为属性和实体类型定义了映射表来解决同义词问题:
- attribute_mapping: 将知识库中使用的属性映射到同义词,如HQ到headquarters
- entity_type_mapping: 将知识库中使用的实体类型映射到特定的实体类型,如,people映射到person
因此,现在你需要做哪些改变呢?除了调用:
|
|
还需要添加如下代码:
|
|
这样你就能够确保你再query中使用的属性是存在的。但是,你需要确保将你的属性的所有的变种添加到映射表中,否则query会失败。
entity type也要做一样的事情:
|
|
解决类似于“the first one”的指代
让我们看一下对话:
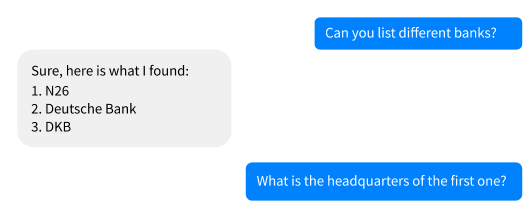
用户指代first bank,如N26.为了查找headquarders,你需要解决这个指代。我们该怎么做呢?下面的代码并不会工作,bank并没有被显示的提出来,因此NER并不会从问题“what is the headquarters of the first one?”检测到bank。
|
|
NER可以将“first one”作为实体提取出来,此外,banking bot还有一个映射表,mention_mapping,用来将特定的指代映射到具体的位置。因此,你可以使用提取出来的指代和mention_mapping,获取实体对应的index位置。
|
|
这样就获取了index。无论什么时候通过query_entities列出一些实体,实体都是存储在listed_items slots中。你可以使用这个list,获取确切的实体:
|
|
这样你就成功的将"first one"解析成了N26。
自定义action的代码
其他的actions的表现是类似的。你提取到NER找到的实体,如果需要,使用映射表进行映射。如果所有需要的部分都得到了,构建query,执行query,从知识库中检索信息。检索得到的结果格式化成回复,如果需要,对slot进行填充。详细可以参见:code。
反馈
如果你有任何问题,可以在Rasa Community Forum提出。
原文链接
https://blog.rasa.com/integrating-rasa-with-knowledge-bases/
Author grassofsky
LastMod 2019-12-21