rasa blog - 深入理解rasa NLU: Part2 - 实体识别 (翻译)
Contents
rasa blog - 深入理解rasa NLU: Part2 - 实体识别 (翻译)
欢迎来到Rasa NLU深入裂解系列的第二部分。在这个系列的文章中,我们会将从社区以及客户中获取的关于Rasa NLU的最佳实践和经验分享给大家。第一部分rasa blog - 深入理解rasa NLU: Part1 - 意图分类 (翻译)介绍了Rasa NLU意图分类器组件,该组件能够最好的适用于你的AI助手。
对用户意图的理解仅仅是问题中的一个部分。从用户消息中提取出相关的信息也是很重要的部分,比如提取日期和地址。提取需要的信息的过程被称作实体识别。针对想要提取的不同的实体,Rasa NLU提供了不同的组件。接着该系列文章,这篇博客将详细解释所有可能的选择以及最佳实践,包括:
- 实体提取组件针对的实体类型
- 怎样去处理常见问题:如模糊实体、地址提取和实体映射
提取实体
作为开源框架,RasaNLU特别注重完全可定制化。Rasa NLU为你提供了多个实体识别的组件,帮助你完成以下自定义需求:
- 使用SpaCy语言模型进行实体识别:ner_spacy
- 使用Facebook的Duckling实现基于规则的实体识别:ner_http_duckling
- 针对自定义实体训练实体提取器:ner_crf
SpaCy
spaCy库提供了预训练实体提取器。和词嵌入类似,只支持部分语言。如果你的语言被支持,那么建议ner_spacy来识别实体,比如组织名字,人名,或地点。你可以在 interactive demo of spaCy尝试使用该实体提取器。
Duckling
Duckling是Facebook开发的基于规则的实体提取库。如果你想要提取任何信息中的数字,如,钱,日期,距离,或时间长度,这个工具是一个很好的选择。Duckling是用Haskell开发的,不支持python库调用。为了和Duckling实现通信,Rasa NLU使用了Duckling的REST接口。因此,当你在你的NLU管道中包含ner_duckling_http 组件的时候,必须运行Duckling服务。运行该服务最简单的方式是,使用我们提供了docker镜像(rasa/rasa_duckling),然后以命令运行docker run -p 8000:8000 rasa/rasa_duckling。
NER_CRF
由于ner_spacy和ner_duckling是基于预训练分类器(spaCy)或基于规则(duckling)实现的,所以你不需要对你的训练数据进行标注。ner_crf 组件需要训练一个conditional random field,它会被用作用户消息实体标注。由于该组件是从零开始进行训练的,因此你必须对你的训练数据进行标注。下面是文档中的一个示例example from our documentation:
|
|
当你没法使用基于规则的或基于预训练的组件的时候,请使用NER_CRF。由于该组件是从零开始进行训练的,因此在进行数据标记的时候需要注意:
- 针对每个实体提供足够的示例(> 20),使得条件随机场能够泛化,和挑选到数据
- 在你的训练数据的任何地方进行标记,即使实体和该意图不相关
正则表达式/ 查找表
为了支持ner_crf组件的实体提取,你可以使用正则化表达式,或查找表。正则化表达式用来匹配某个硬编码的模式,如,[0-9]{5}会匹配5个数字的右边。当你的实体有一些列预定义值的时候,查找表是有用的。比如,实体country最多只有195个不同的值。为了使用正则表达式或查找表,管道中intent_entity_featurizer_regex component需要定义在ner_crf组件之前。然后在你的训练数据中做标记,详细介绍见:documentation.
|
|
正则化和查找表通过标记一个单词是不是被正则化或查找表匹配的方式,向ner_crf添加了额外的特征信息。由于它仅仅是众多特征中的一个,组件ner_crf仍然可能忽略被匹配的实体,但不管怎么说,ner_crf在通常情况下还是偏向于这些特征。注意,这也会阻碍条件向量场的泛化:如果你的故事中所有的实体示例都被正则化表达式匹配了,那么条件随机场只会注意正则表达式的特征,而会忽略其他的特征。那么这个时候出现一个带有实体的消息,但没有被正则化表达式匹配,ner_crf很有可能无法检测到它。尤其是在使用查找表的时候容易出现过拟合的现象。
如果你任然不知道更好使用哪个组件,那么可以参见下面的图表帮助你进行选择:
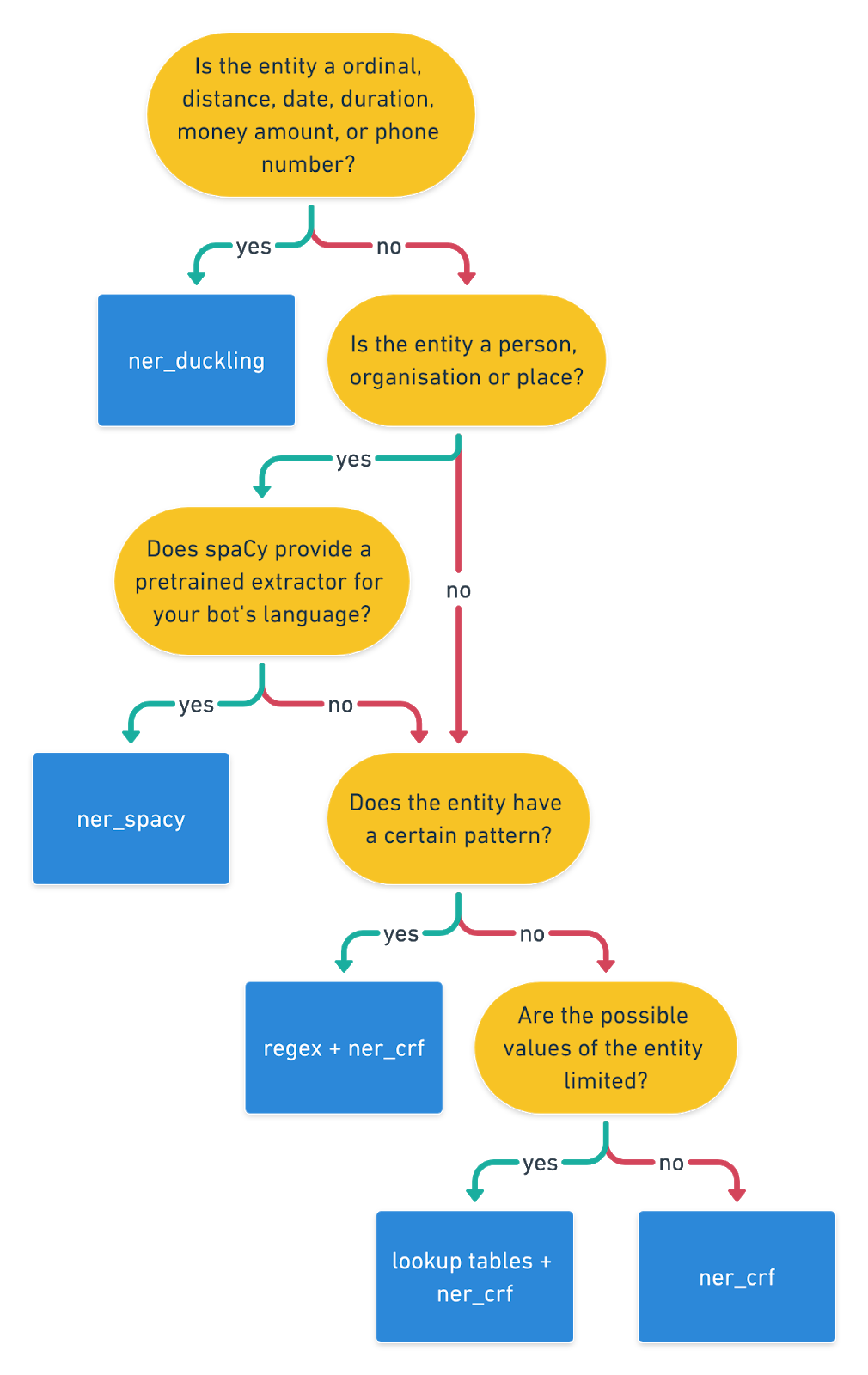
常见问题
Entities Are Not Generalizing
如果你的实体提取器并没有得到很好的泛化,那么可能有两个原因:缺少训练数据及,或ner_crf组件出现了过拟合。如果你使用了很多正则化表达式,或查找表,那么可以试着不使用他们,然后再训练你的模型,观察你的模型是否会出现过拟合。否则,针对你的实体增加更多的训练示例。
地址提取
如果你想要提取地址,那么我们建议使用带查找表的ner_crf组件。在文章blog article on lookup tables中介绍了从类似于 openaddresses.io的数据源中生成你的查找表,然后使用生成的城市和国家列表去支持你的ner_crf。
实体映射
有些时候,提取的实体虽然具有相同的含义,但是有不同的表现形式。比如,你提取国家,如,U.S.,USA,United dStates of America,这三种表述方式都是同一个同价。如果你想要将它们映射到特定的值,你可以使用ner_synonyms组件。在你的训练数据中,你可以进行特定的标记,如下:
|
|
或者使用显示定义的方式:
|
|
小结
该系列的第二部分介绍了使用Rasa NLU实体提取器的最佳实践和建议。通过提供预训练提取器,基于规则的提取器,以及自己训练实现的提取器,你拥有了很强大的工具实现消息中实体的提取,并能够将其应用与AI助手的实现中。完成第二部分的阅读,你应该对于如何选择合适的组件用于实体识别,如何进行配置,如何进行结合使用,抱有很大的信心了。
你已经知道了如何都贱最佳的NLU管道,但是你现在想进入到下一个level。Learn about hyperparameter optimization将是这个系列的最后一篇文章。
原文链接
https://blog.rasa.com/rasa-nlu-in-depth-part-2-entity-recognition/
Author grassofsky
LastMod 2019-12-21