rasa blog - 为Rasa设置知识库来编码领域知识
Contents
rasa blog - 为Rasa设置知识库来编码领域知识
这篇文章紧接着rasa blog - 将Rasa和知识库进行集成。在这篇文章中,你将学习知识库的详细内容,以及如何设置一个。你将学会如何使用知识库中的数据来提高你的NER。
让我们快速的回顾下,当使用知识库解决问题的时候会遇到哪些挑战:
- 回答用户的问题,需要相关的领域知识,如,“What account do I have more money on?”
- 解决指代的实体,如“What is the headquarters of the first bank you just mentioned?”。这里你需要提取出指代实体,并将其解析为之前提到了的真实世界的实体。
这个教程会参考knowledge-base bot的一个实现示例,叫做banking bot,来证明如何设置一个知识库。代码见:here.
什么是知识库
知识库可以用来标识领域知识。通常,会使用图数据库来表示这种知识。图数据库以实体(有时候叫做nodes)、属性、关系的形式来存储数据。用这种形式标识领域知识会显得更加自然。比如,当bank作为一个实体的时候,有name,headquarters,它是否提供免费账户等属性。每个bank有员工,这就是和其他实体形成关联。因此,banks和员工相互关联。使用图数据库使得你能够构建这种复杂的模式。因为图数据库由实体,属性,关系组成,相比较关系型数据库,你可以用更加面向对象的方式进行思考。你甚至可以模拟层次关系。比如,员工是person的特殊类型。你可以将通用属性赋值给person实体,比如birthdate,和state,员工可以从person中集成这些属性,但是具有一些特殊的属性,如role。
如果你只有一些数据点需要存储,那么使用图数据库可能就显得过重了。这个时候,你可以将你的领域知识存储到graph-linke数据结构中,比如字典,作为你的知识库。
如何设置图数据库
为了创建图数据库作为你的知识库,你需要执行三个步骤:
step 1. 决定使用哪个图数据库
需要处理的第一件事情,就是选择一个图数据库。有很多的不同的数据库,如Grakn, neo4j, OrientDB, GraphDB, 每一个都有自己的优缺点。图数据库的选择取决于你的需求。banking bot使用的是Grakn图数据库。对于图数据库并没有一种标准的检索语言,几乎所有的图数据库都有自己的检索语言。Grakn使用graql.如果你想要使用Grakn,可以从这里here.找到安装指南。
step 2. 决定一个模式
在将数据存储到你的图数据库之前,你需要设计模式。需要考虑如下内容:
- 你需要哪些实体?
- 这些实体具有哪些属性?
- 他们之前是如何关联的?
让我们看一下banking bot的模式。banking bot有四个实体:bank,person,account,card。每个实体都具有一些属性。比如bank实体有name和headquarters属性。下面的图中可以看到bank的所有属性。
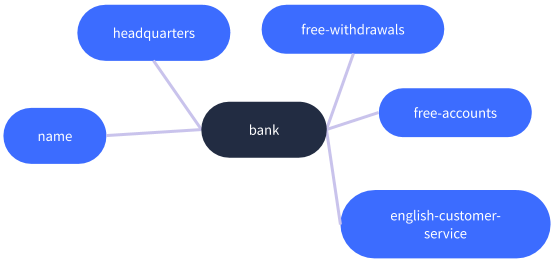
正如前面提到的,图数据库可以存储实体之间的关系。比如,bank与person和account通过关系相连:bank为客户(person)提供一个帐户的合同。下图显示了这种关系。
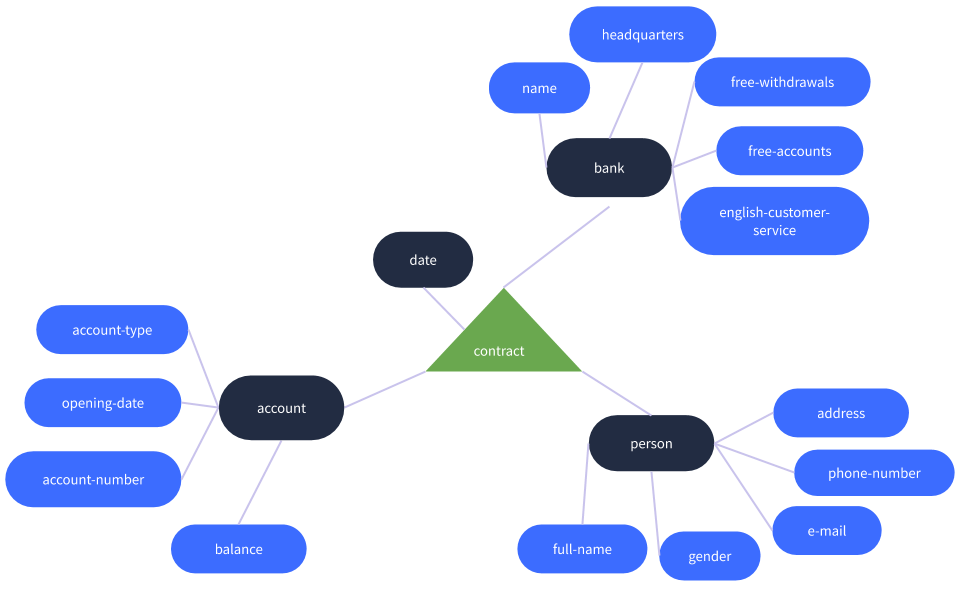
正如你注意到的,关系合同也有一个属性。你可以给关系和实体赋值更多的属性。完整的模式看上去是这样的:
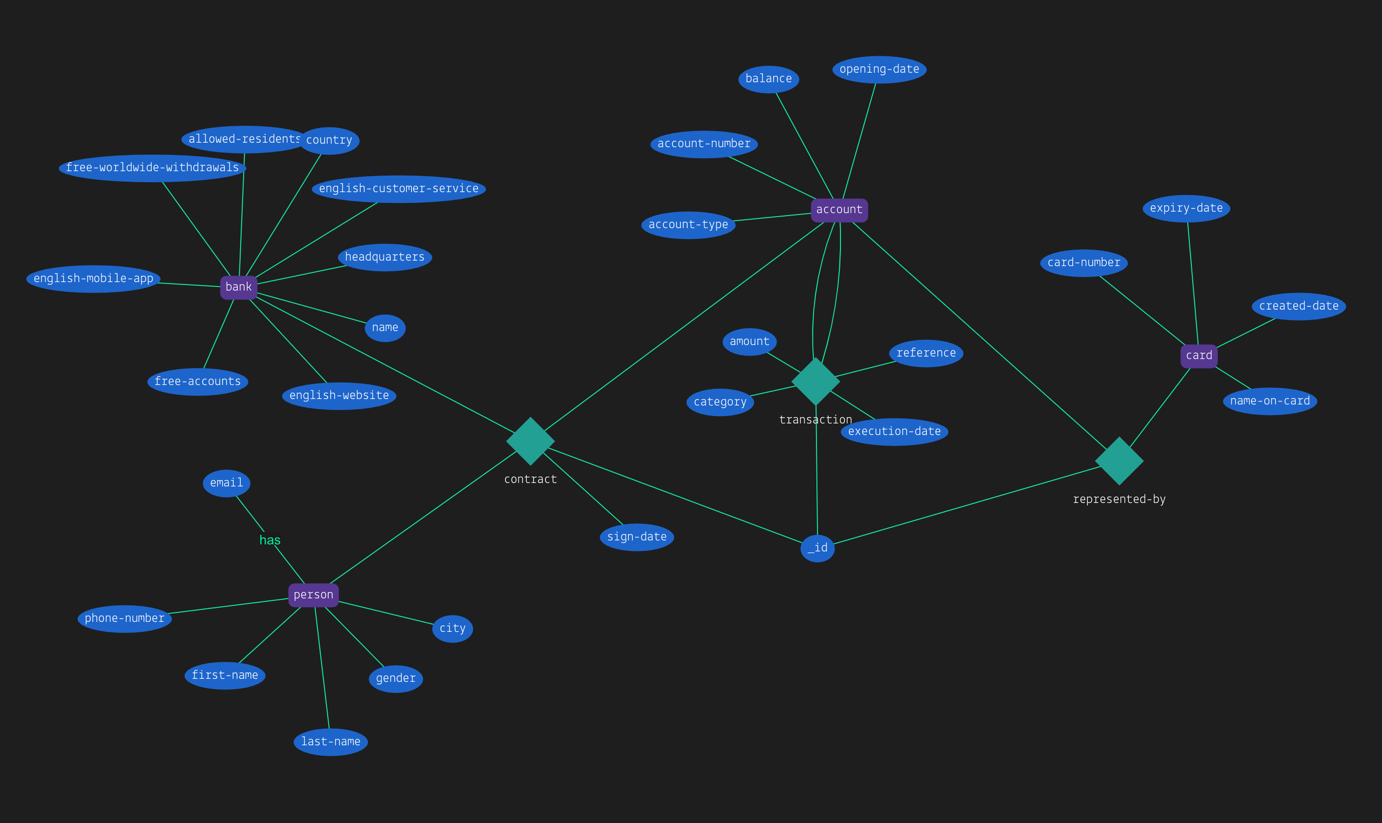
一旦你设计完这个schema,你需要用graql syntax. 进行书写。你可以在here.找到banking bot的完整的schema。为了创建你的schema,你需要执行如下的命令:
|
|
这个将会在你的图数据库中创建一个叫做’banking‘的关键空间,schema定义在’schema.gql‘文件中。
step 3. 将数据加载到图数据库
在创建完schema之后,你需要将数据导入进入。为了将数据导入到我们的schema,Grakn建议写migration script ,允许你将.csv文件中的数据导入到图数据库。banking bot知识库包含几个bank和20个people。每个人最多有三个账号,每个账号最多有上百条交易记录。你可以在here.找到数据和脚本。
到此,你的知识库已经创建了,可以在Rasa中使用它了。
基于数据库的action
banking bot使用上面创建的图数据库,来处理对话中的领域知识。更多的内容,可以参见教程:rasa blog - 将Rasa和知识库进行集成。
为了运行banking bot,克隆tutorial-knowledge-base。然后安装依赖:
|
|
使用rasa train训练模型。在启动bot之前,需要按照README设置知识库。然后,可以启动bot
|
|
下面是与银行机器人的简短对话,展示了机器人如何回答有关其用户帐户和交易的几个问题。
通过添加查找表来优化你的bot
如果缺少上下文环境,NER有时候会丢失实体。比如,如果bot这样问题:
|
|
而你回答'Max’,这对于NER想要检测出对应的人是很困难的。为了优化你的NER,你可以添加查找表。由于你已经有了带很少实体和示例的知识库,我们可以重用他们。
首先,你需要从你的知识库中获取实体,然后将他们写入到文件中。每一个实体类型对应一个文件。下面的query会给你所有的特定entity type的entities:
|
|
结果需要存储到txt文件中。你可以找到小脚本来从你的知识库中提取所有entities,here.请随意调整和重用它。
一旦你有自己的查找变文件,你需要将它添加到NLU训练数据中。假设来自你的知识库中的所有的bank存储在txt文件中data/lookup_tables/bank.txt。你需要在NLU训练数据中添加下面几行,确保训练中能够使用查找表:
|
|
关于查找表更多的信息,可以查看documentation.请注意,为了使查找表有效,培训数据中必须有一些匹配的示例。否则,模型将无法学习使用查找表匹配功能。因此,例如,你应该在培训数据中添加“max”,而不是他的全名,并且在person实体的查找表中还有一个“max”条目。
将查找表添加到训练数据后,需要重新训练模型。此外,如果使用新数据更新查找表,则需要重新训练nlu模型以实际使用新添加的数据。
反馈
如果有任何问题,可以在Rasa Community Forum.提问。
原文链接
https://blog.rasa.com/set-up-a-knowledge-base-to-encode-domain-knowledge-for-rasa/
Author grassofsky
LastMod 2019-12-21