Contents
rasa theory paper - StarSpace: Embed All The Things!(1) - 文章阅读
原文链接
0. 摘要
我们提出了StarSpace,一种通用的神经嵌入模型(neural embedding model),用来处理各种问题:标签任务,如文本分类;排名任务,如信息抽取/web查询,基于协同过滤的推荐系统,基于内容的推荐,多关系图的嵌入,以及学习词、句子或文档嵌入。在每种情况下,模型都是通过嵌入那些由离散特征组成的实体并相互比较来工作的——学习依赖于任务的相似性。一些任务的实证结果显示,StarSpace对于现存的方法而言有高竞争性,同时也适用于这些方法不适用的情况。
1. Introduction
我们介绍的神经嵌入模型StarSpace,能够用来处理很广泛的任务:
- 文本分类,或者其他的标记任务,如情感分类。
- 一系列实体的排名,如,对检索得到的web文档进行排名。
- 基于协同过滤的推荐,如推荐文档,音乐或视频。
- 基于内容的推荐,内容可以定义成离散特征,如文档中的词。
- 学习词,句子或文档嵌入。
StarSpace可以被视为处理这些任务的直接的和有效的强基线。在实验中,它被证明与几种竞争性方法不相上下或优于它们,同时它通常适用于那些许多方法都不适用的情况。
该方法通过从实体集合之间的关系学习具有离散特征表示的实体嵌入,直接用于分类任务或排序任务。一般情况下,StarSpace将不同类型的实体嵌入到一个向量嵌入空间中,因此名字中的Star(*),表示所有类型,space表示空间,在这个空间中对它们进行比较。它学习在给定查询实体、文档或对象的情况下排列一组实体、文档或对象,其中查询不一定与集合中的项属于同一类型。
我们使用6种不同的任务来评估方法的质量,包括文本识别,知识库中的链接预测,文档推荐,文章查找,句子匹配和学习通用的句子嵌入。StarSpace的开源项目见:https://github.com/facebookresearch/Starspace。
2. Related Word
隐藏的文本表示,或者是嵌入(embeddings),是词或文档的向量化表示,通常以非监督的方式从庞大的语料库中学习得到。这个领域中关于神经网络嵌入的工作有:(Bengio et al. 2003),(Collobert et al. 2011),word2vec(Mikolov et al. 2013)和最近的fastText(Bojanowski et al. 2017).在我们的试验中,我们和用于无监督嵌入的可伸缩模型的代表word2vec以及fastText进行了比较,同时还在SentEval(Conneau et al. 2017)任务上进行了句子嵌入的比较。
在监督嵌入的领域中,SSI(Bai et al. 2009)和WSABIE (Weston, Bengio, and Usunier 2011)是早期在NLU或信息提取任务((Weston et al. 2013), (Hermann et al. 2014))中使用的模型。更近一点的工作有:(Tang, Qin, and Liu 2015), (Zhang and LeCun 2015), (Conneau et al. 2016), TagSpace (Weston, Chopra, and Adams 2014) and fastText (Joulin et al. 2016) 在分类任务中,如情感分析或者标签预测中获得了较好的结果。
在推荐系统领域,embedding模型取得了很大的成功,有,SVD(Goldberg et al. 2001)和它的优化如SVD++(Koren and Bell 2015),(Rendle 2010; Lawrence and Urtasun 2009; Shi et al. 2012)。其中许多方法都集中在用户id和电影id具有单独嵌入的协作过滤设置上,例如在Netflix挑战者设置中(参见例如(Koren and Bell 2015),因此新用户或项目不能自然地被合并。我们展示了StarSpace可以自然的满足协作过滤设置和基于内容的设置,用户和项目都被表示成特征,因此具有很自然的扩展性,而不是只考虑固定的集合。
使用基于嵌入的方法执行知识库中的链接预测,在最近几年也显示出比较理想的结果。这个方向中出现了以一些已经完成的工作,如(Bordes et al. 2013)和(Garcia- Duran, Bordes, and Usunier 2015).在我们的工作中,我们展示StarSpace能够被用来处理这类任务,优于几种方法,和TransE方法匹配 (Bordes et al. 2013)。
3. Model
StarSpace模型由学得的entities组成,每个entity由一组来自固定长度字典的离散特征(bag-of-features)描述。一个例如文章或句子的entity可以被描述成bag of words或者是n-grams,类似于用户的实体可以被描述成他们喜欢的文档,电影或项目一类的进行描述。重要的是,StarSpace模型可以用来比较不同类型的实体。比如,用户entity可以和item entity进行比较(推荐系统),或者文档实体和标签实体进行比较(文本分类),等。这取决于他们能够通过学习被嵌入到相同的空间,具有相同的含义 - 通过对感兴趣的指标进行优化。
将$D$特征的字典标记成$F$,$F$是一个$D\times d$的矩阵,$F_i$表示第i个特征(行),产生d维的嵌入,我们将实体a标记为$\sum_{i\in a}F_i$。
也就是,和其他的embedding模型类似,我们的模型给想要直接嵌入的集合中的每个离散特征指定一个d维向量(我们叫做字典,它包含了类似words的特征等)。由特征组成的实体(如文档)被表示成一个由位于字典中的features组成的bag-of-features,和实体的嵌入是隐式学习得到的。注意一个实体可以由单个特征组成,如单个单词,名字或用户或项目ID。
为了训练我们的模型,我们需要学会比较这些实体。明确的,我们想要最小化下面的损失函数:
$\sum_{(a,b)\in E^+,b^-\in E^-}L^{batch}(sim(a,b),sim(a,b_1^-),…,sim(a,b_k^-))$
这个表示中有如下内容需要解释:
- 正实体对$(a,b)$的生成器来自于集合$E^+$。这取决于任务,将在后面描述。
- 负实体$b_i^-$的生成来自于集合$E^-$。我们使用k-negative sampling strategy(Mikolov et al. 2013)每次批量更新选择k个这样的负对。我们随机的从能够出现在第二个参数中的实体集合中进行挑选(比如,对于文本标记任务,a是文本,b是标签,因此我们从标签的集合中采样出$b^-$)。关于k的影响在Sec.4中介绍。
- 相似函数$sim(.,.)$。在我们的系统里实现了cosine相似度和内积,并将选择作为超参数。通常情况下,对于小数量级的标记任务(如,分类)表现结果相似,然而cosine对于大数据量时更加合适,如句子和文本相似度。
- 损失函数$L_{batch}$包含了正对和负对,我们同样实现了两种选项:margin ranking loss(如,$max(0,\mu-sim(a,b))$,其中$\mu$是margin 参数),和softmax的negative log损失。所有的实验都使用前者,因为它的表现相当或更好。
我们使用随机梯度下降(SGD)优化算法,如,每一个SGD步都是从$E^+$获取一个样本,在多CPU上使用Adagrad(Duchi, Hazan, and Singer 2011) 和hog- wild (Recht et al. 2011)。和其他工作一样(Weston, Bengio, and Usunier 2011).,我们也应用了嵌入的max norm将学习到的向量限制在空间$R^d$半径为r的球中。
在测试的时候,我们使用学习到的函数sim(.,.)用来检测不同实体之间的相似度。比如,对于分类任务,使用输入和可能的类别的集合$\hat{b}$,找到满足下式的结果就是预测的类别$max_{\hat{b}}sim(a,\hat{b})$。或者通常情况下,通过他们的相似度,对实体进行排序。或者,嵌入向量可以直接用于其他下游任务,如,就像一般的嵌入模型一样。但是,如果sim(.,.)能够直接满足你的应用的需求,那么建议直接使用,因为这是StarSpace被训练的目标所在。
我们现在描述模型怎样被应用到不同的任务中,每个特定的任务中,如何设定$E^+$,$E^-$等。
多分类任务(如,文本分类) 正对直接来自打标签了的训练集$(a,b)$,其中a是文档(bags-of-words),b是标签(单例特征)。负实体$b^-$是从可能的标签中采样得到的。
多标签分类 这种场景中,每个文档a有多个positive labels,他们中的一个在每个SGD阶段被采样成b,用来实现多标签分类。
基于协同过滤的推荐 训练数据包括用户集,每个用户被描述成用户喜欢的bag of items(从字典中描述的唯一特征)。正对的产生挑选一个用户,选择a作为该用户ID的唯一单例特征,并选择他们喜欢的单个项作为b。从可能的项集合中对负实体b-进行采样。
基于协同过滤的样本外用户推荐 基于协同过滤的推荐有一个问题就是无法推广到新用户,因为每个用户ID都有一个单独的嵌入。使用之前的相同的训练数据,可以使用StarSpace训练一个不一样的模型。相反,正对生成器选择一个用户,选择a作为除一个之外他们喜欢的所有项,选择b作为遗漏项。也就是说,模型通过将用户建模为一个嵌入项的总和,而不是基于他们的ID,来学习判断用户是否想要一个项。
基于内容的推荐 这个Task包括用户集合,每个用户描述成items包,每个item描述成来自字典的特征包(而不是唯一的特征)。比如,针对文档推荐,每个用户描述成他们喜欢的文档包,每个文档描述成它包含的单词包。此时,a可以选择除了一个item之外的所有item,b为漏选的item。那么系统可以扩展到新的item和新的user。
多关系知识图谱(如,链接预测) 给定图谱的三元组(h,r,t),h是head concept,r是关系,t是tail concept,如(Beyonc´e, born-in, Houston), 可以学习这类图的embedding。h,r,t的实例化被词典中唯一的特征定义。我们也会随机选择:(i)a包括特征h和r,b仅仅包括t,或者(ii)a包括h,b包括r和t。负实体b-从可能的概念中采样得到。学习到的embeddings能够被用来回答链接预测的问题,如,(Beyonc´e, born-in, ?)或者(?, born-in, Houston) ,通过学些到的函数sim(a,b)。
信息检索(如,文档查找)和文档嵌入 提供监督的训练数据,包括(查找关键字,相关文档)对,可以直接用来训练信息检索模型:a包括查找的关键字,b是相关的文档,b-是不相关的文档。如果仅有非监督的训练数据,包括没有标签的文档,选择a的方式是从文档中随机选择关键词,b是剩余的单词。注意,两种途径隐式学到的文档embeddings,可以用作其他目的。
学习词嵌入 我们也可以从包含raw文本的训练数据中,使用StarSpace学习非监督的词嵌入。我们选择a为窗口的单词(如,四个单侧,中间词的两边),b为中间词,可见(Collobert et al. 2011; Mikolov et al. 2013; Bojanowski et al. 2017).
学习句子嵌入 对于学习句子嵌入而言,学习单词嵌入(如上文所述)并使用它们来嵌入句子并不是最佳选择。给定没有标记的文档作为训练集,每个都有句子组成,我们选择a和b作为相同文档中选出来的句子对,b-来自不同文档的句子。直觉是一个文章中不同句子的语义相似性是共享的(如果文档特别长,句子选择的时候可以考虑仅选择特定距离范围内的句子)。此外,嵌入将自动针对句子长度的单词集进行优化,因此训练时间与测试时间匹配,而不是像通常使用单词嵌入学习的那样使用短窗口进行训练-当句子中的单词总数过大时,基于窗口的嵌入可能会变差。
多任务学习 如果以上的任务具有相同的base字典F, 他们可以合并,并在同一时间进行训练。比如,可以将监督式分类和无监督的词或句子嵌入相结合,形成半监督学习。
4. Experiments
Text Classification
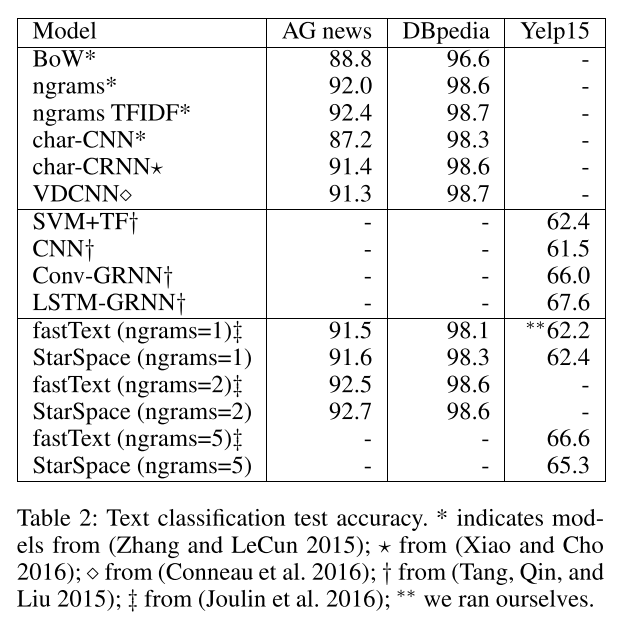
我们将StarSpace用于文本分类任务,并将其与许多竞争方法进行比较,包括fastText,使用了在之前的工作中使用到的三个数据集(Joulin et al. 2016). 为了确保公平比较,我们使用相同的词典,和使用相同的n-grams实现和修剪(这些特征在我们的开源项目中有实现)。在这些实验中,我们设定嵌入的维度为10,和(Joulin et al. 2016)一样。
我们使用三个数据集为:
- AG news:4类文本分类任务,输入为title和描述。它包含120K训练样本,7600测试样本,4类,约100K单词,和5M的tokens。
- DBpedia(Lehmann et al. 2015):14个类别的分类问题,输入为维基百科文章的摘要和标题。包括560K训练数据,70K测试数据,14个类别,约800K单词,和32M token。
- Yelp reviews数据集,从2015 Yelp数据集挑战中获取(https://www.yelp.com/dataset_challenge)。这个任务用来用户给的评分进行预测(1到5)。包括1.2M训练数据,157K测试数据,5类,约500K单词,193Mtoken。
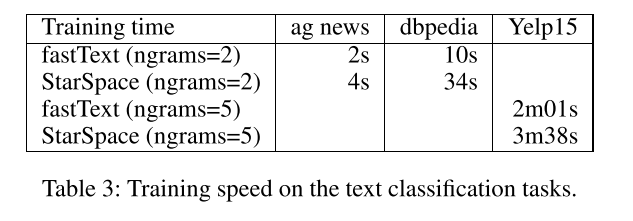
结果显示在表2. 基线是从文献中引用得到的(一些方法仅用于AG news和DBPedia,另一些只用于Yelp15)。StarSpace执行了一系列的方法,和fastText的结果比较一致。在Table3中,我们测试了n-grams>1时训练的速度。与深度学习方法相比,如(Zhang and LeCun 2015)在数据及DBpedia上每一次epoch需要花费5h,fastText和StarSpace都很有效。但是在接下来的章节中,我们可以看到starspace是一个更加通用的系统。
Content-based Document Recommendation
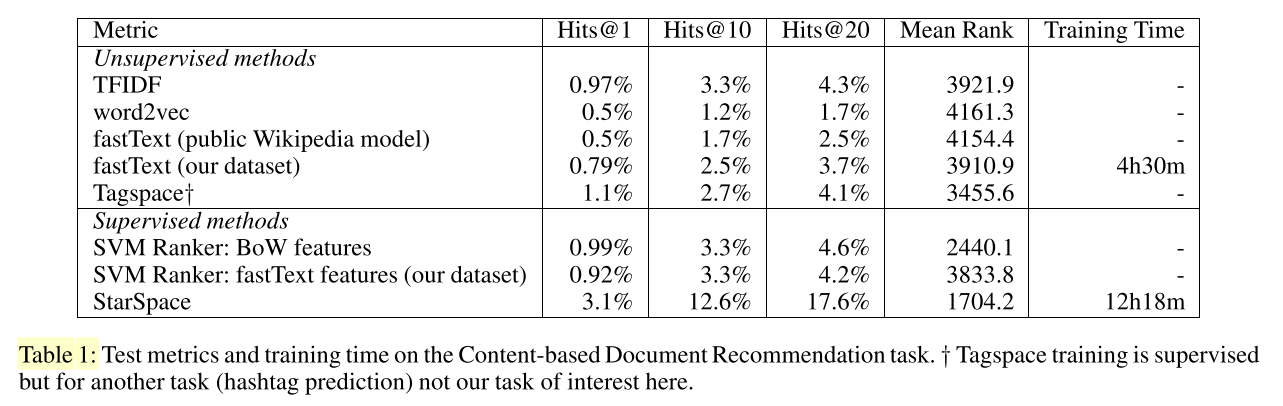
我们考虑根据用户历史喜欢的文档推送新的文档的任务。在实验中,我们采用和(Weston, Chopra, and Adams 2014) 非常相似的处理流程。这个任务的数据由一个流行的社交网络服务上的一部分人的匿名两周的交互历史组成。在考虑的641385人中,我们收集了他/她点击阅读的公共文章的文本,共给出3119999篇文章。考虑到此人的后续(n-1)点击文章,我们使用我们的模型预测第n篇文章,将其与10000个其他不相关的文章进行排序,并使用排名指标进行评估。通过应用StarSpace获取的第n篇文章的分数:a是之前的n-1篇文章,b是候选的第n篇文章。我们通过计算hit@k,如,正确实体位于前k的比例(k=1,10,20),以及点击文章在10000篇文章中的平均预测排名来衡量结果。
由于这不是一个分类问题(如,没有一组固定的标签可供分类,而是一组以前从未见过的按用户排列的文档)我们不能直接使用监督分类模型。但是,Starspace能够直接处理这种任务,这是他的主要好处之一。依据(Weston, Chopra, and Adams 2014),我们使用下面的模型作为baselines:
- Word2vec模型。我们使用公共的google news文中(https://code.google.com/archive/p/word2vec/)训练得到的word2vec,使用词向量生成文章的embeddings(bag-of-words)和用户的embedding(通过用户历史点击任务bag-of-articles)。我们然后使用cosine相似度用于排序。
- 非监督的fastText模型。我们使用之前在维基百科上面训练得到的模型(https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md),来训练我们自己的数据集。非监督的fastText是word2vec的增强,同时包括subwords。
- 线性SVM ranker,使用bag-of-words特征,或fastText嵌入(同维a和b特征的成分相乘,他们具有相同的维度)。
- 在hashtag task训练得到的Tagspace模型,然后嵌入被用于文档推荐,重新制作于(Weston, Chopra, and Adams 2014). 在这个工作中,Tagspace的效果优于word2vec。
- TFIDF bag-of-words cosine相似模型。
为了公平比较,我们将所有的embedding模型设置的维度时300.在Table1中我们显示了我们Starspace的模型结果和baseline模型的结果。starspace和fastTet(Bojanowski et al. 2017)的训练时间也提供了。
Tagspace先前显示为word2vec提供了更好的性能,我们在这里观察到了相同的结果。无监督的FastText是word2vec的一个增强,它也稍逊于Tagspace,但优于word2vec。但是starspace看上去更加适合于这个任务,优于所有这些方法,包括标记空间和支持向量机。总的来说,从评估中可以看出,无监督的单词嵌入学习方法不如专门针对文档推荐任务的训练,而StarSpace就是这样做的。
Link Prediction: Embedding Multi-relation Knowledge Graphs
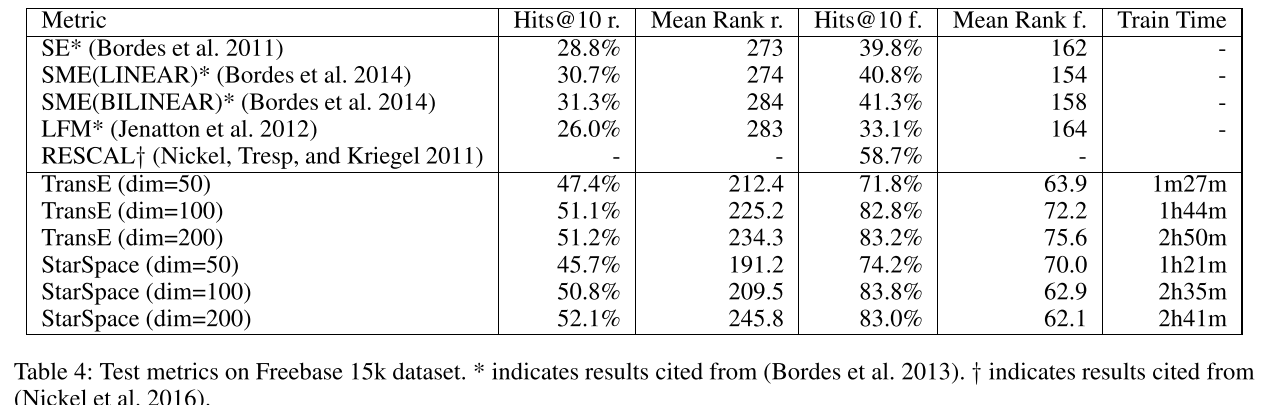
我们提到过,starspace能够用来处理知识表示的任务。我们使用Freebase 15k数据集(Bordes et al. 2013),该数据集包含了从Freebase(http://www.freebase.com)提取的三元组集合。这个数据集可以看作是一个描述句法集之间三元关系的三模张量。共有14951个概念(mids)和1345个关系类型。训练集包含483142个三元体、50000个验证集和59071个测试集。正如(Bordes et al. 2013)中描述的,评估是这么执行的,针对每个测试三元组,移除头并依次用字典中的实体替换。先用模型对这些三元体进行打分,并排序;正确实体的排序等级会被记录下来。整个流程在对tail进行处理的时候会重复一遍。我们报告这些预测等级的平均值和hits@10。我们还按照(Bordes et al. 2013)执行了相同的筛选评估,除了所有的训练集或测试集中的有效的头或尾都被排除。
我们比较了许多方法,包括transE(Bordes et al. 2013)。TransE显示出效果优于RESCAL (Nickel, Tresp, and Kriegel 2011), RFM (Jenatton et al. 2012), SE (Bordes et al. 2011) 和 SME (Bordes et al. 2014) ,并且被认为是标准的基准方法。TransE使用了L2相似性,$||head+relation-tail||^2$和SGD更新,头部或尾部单个实体的变化会带来更大的距离。相比较而言,starspace使用了点积,k-negative采样,和两个不同的嵌入来表示关系实体,依赖于出现在a或者b中。
结果显示在Table4.SE, SME 和LFM的结果来自于(Bordes et al. 2013),将维度作为超参数(20,50,75)进行优化。RESCAL来自(Nickel et al. 2016)。对于TransE,我们自己运行了该模型,因此我们可以得到不同嵌入维度的结果,因为我们对参数进行了微调,获得了比报告中更好的结果。在相同维度的时候,对TransE和StarSpace进行比较,这两个方法得到相近的效果。注意,针对该数据集使用大的embeddings已经获取了结果的提升 (Kadlec, Bajgar, and Kleindienst 2017),或者使用更加复杂的,不通用的模型(Shen et al. 2017)。
K的影响 在这一节,我们在freebase 15k数据集上进行试验,根据负搜索例子的数量来说明我们模型的复杂度。我们设置dim = 50,算法最大的训练时间大概为1小时。我们报告算法在特定的时间限制内完成的epochs的数量,同时还报告了对于不同k(每个正训练示例搜索的否定数)的可能学习率选择的最佳筛选结果hits@10。我们设置k=[1,5,10,25,50,100,250,500,1000]。
结果显示在Table5. 我们观察到在1小时训练时间限制内完成的阶段数接近于k的一个逆线性函数。在这个特定的设置中,[1, 100 ]是k的良好范围,并且在k=50时达到最好的结果。

Wikipedia Article Search & Sentence Matching
在这一节,我们将我们的模型应用到wikipedia文章的搜索和句子匹配的问题。我们使用(Chen et al. 2017)引入的维基百科数据集,是英文维基百科2016-12-21的dump。对于每一篇文章,只提取纯文本,所有结构化数据部分(如列表和图)都被剥离。总共包括5075182篇文章,9008962 unique uncased token types。数据集被划分为,5035182训练示例,10000验证集,10000测试集。我们考虑到如下的评估任务:
- Task 1:给定一个来自维基百科文章的句子作为搜索查询,我们试图找到它来自维基百科的文章。我们使用排名评估指标对真实的维基百科文章(减去句子)与其他10000篇维基百科文章进行排名。这模拟了一个类似于web搜索的场景,我们希望在其中搜索最相关的Wikipedia文章(web文档)。请注意,我们有效地监督了此任务的培训数据。
- Task 2:从维基百科的一篇文章中随机选取两个句子,用其中一个作为搜索查询,并尝试找到来自同一原始文档的另一个句子。我们将真实的句子与来自不同维基百科文章的10000个句子进行比较。这符合这样一种情况:我们希望找到与主题语义密切相关的句子(但不一定有很强的词重叠)。还要注意,我们有效地监督了这项任务的培训数据。
我们可以用一下方式训练我们的starspace模型:每一个step都从我们的训练集中选择一篇wiki文章。然后,从文章中随机挑选出一个句子作为输入,针对于Task2,还需要随机挑选出另一个句子作为label(针对于Task1,就是挑剩下的文章内容)。negative entities可以随机的从训练集中挑选。针对于Task1训练的案例,对于标签特征,我们使用0.8的特征丢失概率,这既规范了训练,又大大加快了训练速度。我们也尝试了starspace单词级别的训练,同时用于task2的句子和单词级别的多任务。
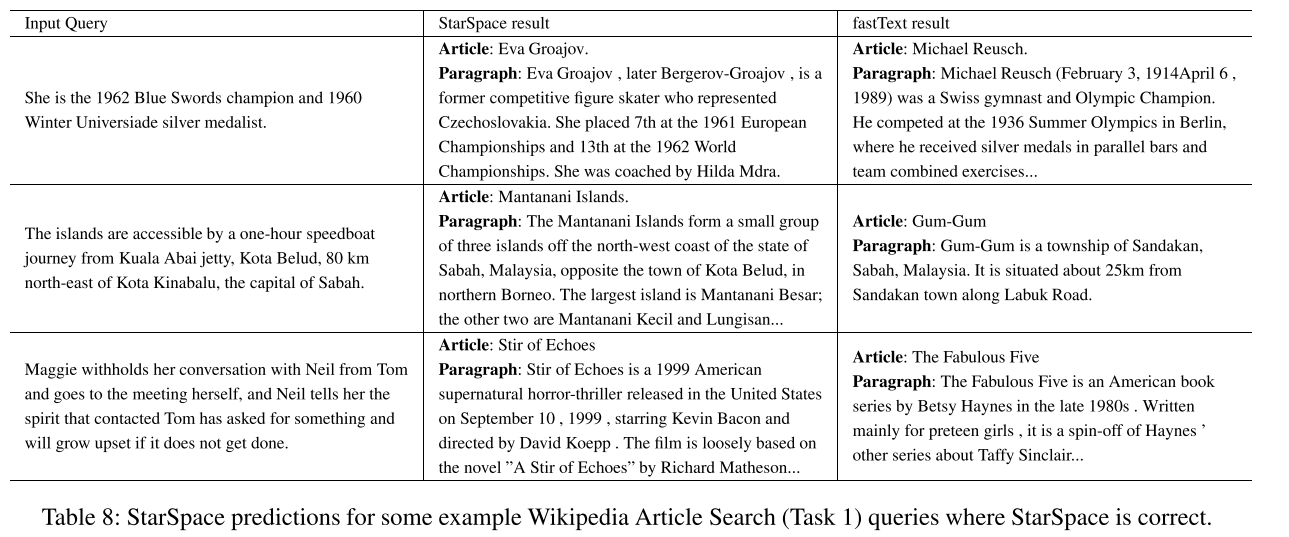
我们用公开发布的fastText模型和starspace进行了比较,同时也和针对我们的数据集训练的fastText进行了比较。我们还和TFIDF基线进行了比较。为了公平比较,我们将嵌入模型的维度都设置成300.针对Task1和Task2的结果总结在Table6和7中。StarSpace比TFIDF和fastText有很大的优势,这是因为starspace能够直接针对感兴趣的任务进行训练,而它不在fastText的声明范围内。注意,StarSpace单词级训练在方法上类似于fastText,其结果与fastText相似。至关重要的是,starspace的句子和文档级训练能力带来了性能提升。
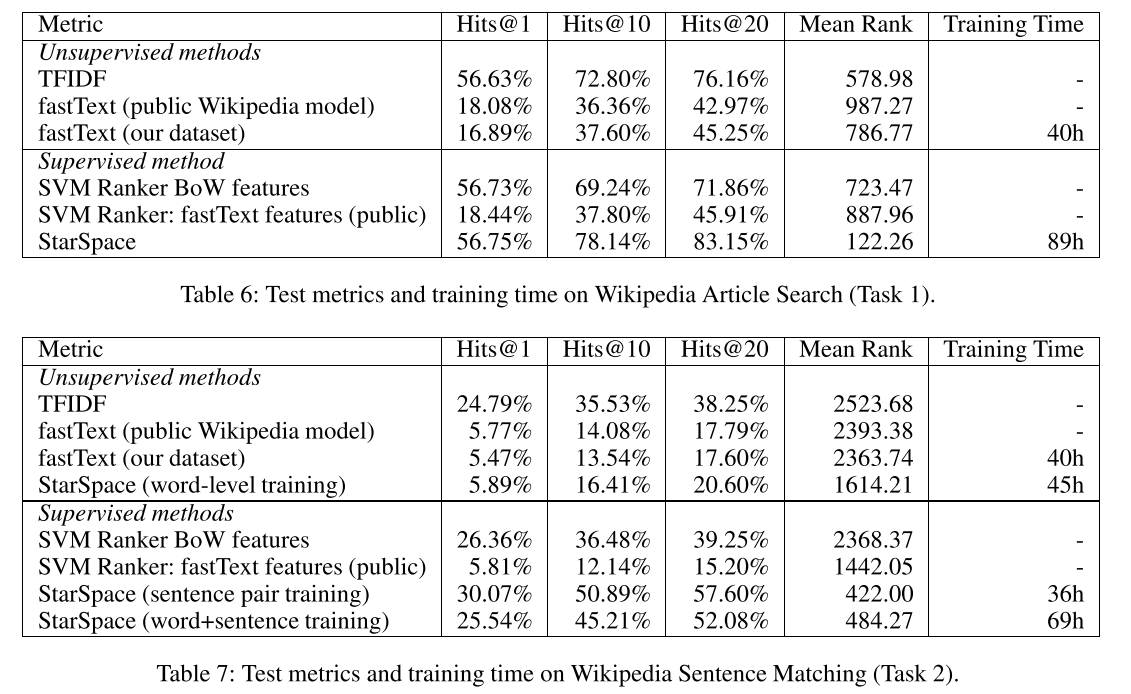
表8比较了starspace和fastText在文章搜索任务(任务1)中对一些随机查询的预测。虽然fastText结果在语义上大致位于空间的正确部分,但它们缺乏更精确的预处理。例如,第一个查询是查找有关奥林匹克滑冰运动员的文章,StarSpace正确理解这些文章,而fastText选择奥林匹克体操运动员。请注意,查询中并没有特别提到skater这个词,星际空间只能通过理解相关短语来理解这一点,例如短语“Blue Swords”指的是国际花样滑冰比赛.另外两个例子得出了类似的结论。
Learning Sentence Embeddings
这一节,我们评估了句子嵌入使用我们的模型和SentEval(https://github.com/facebookresearch/SentEval)((Con- neau et al. 2017) ,用于检测通用目的的句子嵌入的质量)。我们使用了14个转移任务,包括二元分类、多类分类、蕴涵、释义检测、语义关联和语义文本相似度。有关这些传输任务和基线模型的详细说明,请参见(Conneau et al. 2017)。
我们在上一节的Wikipedia Task 2中训练以下模型,并评估由这些模型生成的句子嵌入:
- starspace在单词级别上进行训练
- starspace在句子级别上进行训练
- starspace在单词和句子级别进行训练(multi-tasked)
- 在单词和句子两个层次上训练的starspace模型集合:我们训练一组13个模型,在维基百科上进行多任务句子匹配和单词层次训练,然后将所有嵌入连接在一起,为每个单词生成一个13×300=3900维的嵌入。
我们将结果显示在table9和table10中。starspace表现的更好,超过了很多方法,尽管没有一种方法能在所有的任务中完全获胜。特别在STS(Semantic Textual Similarity)任务,starspace有很好的结果。这些数据集的进一步结果和分析,请参考(Conneau et al. 2017)。
5. Discussion and Conclusion
本文提出了一种利用实体间关系对实体进行嵌入和排序的方法StarSpace,并证明了该方法是一个能够处理多种任务的通用系统:
- 文本分类、情感分析:显示了我们的方法相比较fastText而言(Joulin et al. 2016)在三种不同的数据集上获取了好的结果
- 基于内容的推荐:能够直接解决这一类的任务,然而应用off-the-shelf fastText, Tagspace 或者 word2vec,得到较差的结果。
- 知识库链接预测:我们证明我们的方法优于几种方法,在Freebase 15K数据集上和TransE保持一致(Bordes et al. 2013)。
- 维基搜索和句子匹配任务:由于直接训练句子和文档级的嵌入,它比现成的嵌入模型有更好的性能。
- 学习句子嵌入:它在14个SentEval迁移任务上与许多嵌入方法相比表现的更好。
StarSpace也能很好的应用于我们之前没有评估过的其他任务,比如其他的分类任务,排序,检索和度量学习任务。重要的是,与现有的许多嵌入模型相比,我们的方法更一般:(i)使用特征来表示要分类或排序的标签的灵活性,这使得它能够直接在下游预测/排序任务上进行训练;以及(ii)选择适合这些任务的积极和消极因素的不同方法。如表7所示,选择错误E+和E- gnereator会产生非常差的结果。
未来的工作将考虑以下增强:不再限制于离散特征,例如连续特征,考虑非线性表示,并试验其他实体,例如图像。最后,虽然我们的模型是相对有效的,但是我们可以像FastText一样考虑层次分类方案,以使其更有效;这里的诀窍是这样做,同时保持我们的模型的通用性,这正是它如此吸引人的原因。
相关链接
Author grassofsky
LastMod 0001-01-01