9. 在深度的对象
Contents
原文: https://paroj.github.io/gltut/
第五章 在深度的对象
在这一章中,我们将会处理如何渲染多个对象,特别是当多个对象之间有一定的重叠的时候。
opengl中的多个对象
首先需要知道的是对于相互重叠的多个对象进行绘制的时候发生了什么。这个概念的介绍对于后续内容的理解将起到一定的帮助作用。
一个对象,在绘制过程中,可以被认为是一次draw调用产生的结果。因此,一个对象是由一系列的小三角形组成的,还带有自己独立的对象属性。
顶点数组对象
到目前为止,每当我们进行一些绘制的时候,我们需要做一些准备工作。如,设置顶点着色器中需要用到的各个顶点的属性:
- 使用glEnableVertexAttribArray来激活属性
- 使用glBindBuffer(GL_ARRAY_BUFFER)将上下文和缓存对象进行绑定,对象中含有顶点的属性。
- 使用glVertexAttribPointer来定义上一条中绑定的缓存对象中的数据格式。
拥有越多的属性,就说明在具体的渲染工作之前需要更多的准备工作。为了减轻准备工作的负担,opengl提供了用来存储这些状态的对象:顶点数组对象(VAO, Vertex Array Object)。
VAO通过glGenVertexArray函数进行创建。其使用方式类似于glGenBuffers。通过这个函数的一次调用,可以创建多个对象。对象使用GLuints来表示的。
接着,使用glGenVertexArray将创建的对象绑定到上下文中。这个函数不想glBindBuffer需要指定目标位置。因为,他仅能够使用VAO进行绑定。
一旦VAO绑定后。可以通过调用一些函数来改变绑定到VAO的一些数据。技术上来将就是改变VAO的状态。上述讲到的内容可以总结为两句话:
|
|
上面的语句创建了单个vao。下面的函数用来改变vao的状态,因此如果当前没有绑定vao,就进行下面的函数的调用,调用就会不起作用。
- glVertexAttribPointer
- glEnableVertexAttribArray/glDisableVertexAttribArray
- glBindBuffer(GL_ELEMENT_ARRAY_BUFFER),这个函数不经过vao的绑定进行调用是不会失败的。
buffer binding和attribute association 你也许会注意到,glBindBuffer(GL_ARRAY_BUFFER)并没有出现在上述的函数中,尽管该函数也属于渲染属性设置的一部分。这是因为调用glBindBuffer(GL_ARRAY_BUFFER)的时候,并没有将缓存对象和顶点属性进行绑定。这两者之间的关联性是在你调用glVertexAttribPointer的时候建立起来的。
当你调用glVertexAttribPointer函数的时候,opengl直接将与顶点属性相关联的缓存区直接绑定到了GL_ARRAY_BUFFER上。试想一下,GL_ARRAY_BUFFER绑定的是glVertexAttribPointer能够读取的全局指针变量。因此,在调用glVertexAttribPointer之后,对于GL_ARRAY_BUFFER绑定的对像进行更改是不会产生影响的。因此,VAO存储与属性相关的缓存对象,并不存储通过GL_ARRAY_BUFFER绑定的对象。
如果你想要知道为什么在不使用vao的时候,glVertexAttribPointer没有使用这种缓存对象获取的方式,而是使用bind+call的方式,这是api遗留技术。当缓存对象最早被引入的时候,为了尽量上的影响现有api的调用。原先的glVertexAttribPointer设计成了依赖于缓存对象是否绑定到了GL_ARRAY_BUFFER。而现在,如果没有缓存对象绑定到GL_ARRAY_BUFFER,直接调用该函数就会引发错误,成为了一种让人恼火的事情了。
这样就允许我们在后期调用渲染函数的时候,只要绑定当前创建的vao即可。在使用的时候,有一点需要注意的是,vao中存储的状态并不是永恒不变的。上述任何函数的调用都会引起vao内部状态的变化。
基于索引的绘制
在上一章中,我们绘制了长方体。如果你仔细查看顶点的数据,你会发现其中很多个顶点数值是重复的。为了绘制立方体的一个面,我们需要绘制两个三角形,需要6个顶点,其中有两个顶点是相同的。
对于上例中的简单的问题,重复点的数量是比较少的。但是考虑到一个立方体有六个面,每个面有四个点,这样需要24个点,但是每个面是以三角形为基本单位进行绘制的,因此总共需要6×6=36个点。那么再想象一下,对于类似与人体这样复杂的表面的构建,需要的点的数量将是及其庞大的,重复的点的出现会占用很多的内存空间。而将重复的数据移除,在一定程度上可以将顶点的数量缩减到一半甚至更多。
为了一处多余的点,我们必须采用基于索引的绘制方式。而不是基于数组的绘制方式。在早一些的章节中,我们给出了glDrawArrays的伪代码:
Example 5.1 Draw Arrays Implementation
|
|
这就描述了基于数组的绘制是怎么工作的。你给出了绘制的起点,以及个数。
为了在多个三角形中共享相同的数据,我们需要随机的访问属性数组,而不是线性的进行访问。这是通过索引数组实现的。
假设我们的属性数值如下:
|
|
你可以使用glDrawArrays来绘制前三个点组成的三角形,或是后三个点组成的三角形。但是通过合理的索引数组可以实现绘制四个三角形。
|
|
这会使得opengl产生如下顺序的点:
|
|
12个顶点产生四个三角形。现在我们已经知道了基于索引的绘制是怎么实现的了,我们需要通过opengl来进一步的实现。索引绘制需要两件事情:一个合理构建的索引数组和一个新的绘制命令。
索引数组也存储在缓存对象中。他的绑定的位点是,GL_ELEMENT_ARRAY_BUFFER。你可以像使用GL_ARRAY_BUFFER一样处理这个位点。索引绘制的前提必须是一个缓存对象绑定到了GL_ELEMENT_ARRAY_BUFFER,并且索引数组是来自这个绑定了的对象。
Note
opengl中所有的缓存对象除了绑定位点不同外,其他的都是一样的,同时一个缓存对象可以绑定到不同的目标上。那么同一个缓存对象来存储顶点属性和索引数组完全是合理的。显然,不同的数据可以存储在缓存对象的不同区域。
在将缓存对象绑定到GL_ELEMENT_ARRAY_BUFFER之后,需要调用glDrawElements进行绘制,函数如下:
|
|
第一个参数和glDrawArrays的第一个参数是一样的,表示绘制的类型。count表示有多少个索引值会从数组中取出来。type表示索引值的类型。可以是,GL_UNSIGNED_SHORT, GL_UNSIGNED_BYTE, GL_UNSIGNED_INT。注意的是,这个类型必须是unsigned的。最后一个参数是从数组中取值的字节偏移量。
用伪代码实现如下:
Example 5.2 Draw Elements implementation
|
|
elementArray表示的是绑定到GL_ELEMENT_ARRAY_BUFFER上的缓存对象。
多个对象
这一章中的例子,使用多个vao来绘制两个独立的对象。这些对象均是基于索引绘制的。一种方法是将所有的属性存储在一个数组中。
这里,我们即将绘制的两个对象都是楔子,只是一个是横着放一个是竖着放。相对于之前的例子,着色器并没有太大的变化。我们会使用上一章中介绍的透视矩阵。初始化的代码有所改变,如下:
|
|
这个初始化vao的代码看上去比较复杂,但是仔细看这些代码基本都是在上述例子的渲染过程中出现过的。由于所有的数值都存储在一个数组中,因此对于glVertexAttribPointer中需要的偏移量的计算就变得比较复杂了。
总结一下上面一段代码干了些什么,不外乎是创建了2个vao,然后进行绑定,设定他们的状态。再次强调的是,GL_ARRAY_BUFFER并不是vao状态的一部分,而GL_ELEMENT_ARRAY_BUFFER则是。因此,这两个vao存储了属性数组数据和元素索引缓存数据,除了需要显示的调用绘制命令外的其他的准备工作均完成了。
在这个例子中,两个对象共同拥有相同的索引缓存对象。但是索引缓存是每个vao状态的一部分,因此要分别均进行设置。还有一点需要注意的是,GL_ARRAY_BUFFER不像GL_ELEMENT_ARRAY_BUFFER一样,仅仅绑定了一次。
Note
如果你仔细看下我们的数组中顶点位置属性,发现只有三个维度,而在着色器中我们使用的是vec4.其实,opengl可以自动对缺少的维度进行处理,第一二三个维度默认为0,第四个维度默认为1。
尽管初始化的代码看上去比较复杂,而渲染工作的代码比较而言是相当简单的。
Example 5.4 VAO and Indexed Rendering Code
|
|
运行后得到的结果为:
Figure 5.1 Overlapping Objects

途中两个对象其实是相同的,只是一个是竖的,一个是横的。但是一个看起来比较小,是因为它处在比较远的地方,那么为什么这个比较远的对象反而将比较近的对象的一部分给遮挡了呢?
在解决这个问题之前,我们首先来看个别的问题。
优化:基本的顶点
使用vao对象可以显著的简化代码。但是,vao并不总是提高性能最好的方案,尤其是当你使用了很多相互独立的缓存对象的时候。
绑定vao用于渲染,是一个比较费性能的举措。因此,如果存在一种方法可以避免vao的绑定,那么可以提高当前因为cpu的瓶颈而卡壳的性能。
我们给出的两个对象是非常普通的。他们使用相同的顶点属性片段,因此他们会和相同的项目对象进行渲染。两个对象之间唯一的区别是设置的偏移的不同。
来看一下缓存对象中的顶点数据。
Example 5.5 Vertex Attribute Data Abridged«»
|
|
可以观察到对象2的属性直接位于对象1的属性之后。因此,我们需要的仅仅是两个属性数组,而不是四个。如果我们用基于数组的绘制,我们可以简单的只是用一个vao对象。整个渲染将会变成类似如下的代码:
|
|
对于基于数组的绘制而言上述是可以的,但是我们是基于index的绘制。而且我们也可以通过glDrawElements函数中的count和indices两个参数实现对获取的元素的控制。我们需要做的就是改变索引数据。如下:
Example 5.7 MultiObject Element Buffer
|
|
对于我们这个简单的例子而言,这样实现是有效的。但是,这样会增加空间的占用。更好的一种方式是对获取的索引值在与属性数据相关之前进行一个偏移。
我确信你会对于opengl提供这样的一个机制而感到吃惊。
函数glDrawElementsBaseVertex提供了这样的一个机制。它的工作方式类似与glDrawElements,但多了一个对于每个值产生偏移的入参。下面的例子就说明了如何用这个函数:
Example 5.8 Base Vertex Single VAO
|
|
Example 5.9 Base Vertex Rendering
|
|
Note
上面使用BaseVertex的例子看上去可能有点假,因为两个对象的index data是相同的。更常见的方式是和拥有不同index data的对象一起使用的。当然,如果一个对象有不同的index data,你也许会觉得你可以人为地创建一个新的element buffer,并将偏移量添加上去。
这里有几个不建议这样做的理由。其中一个是,GL_UNSIGNED_INT占用的空间是GL_UNSIGNED_SHORT的两倍。如果你有比65536还要多的组分,你会使用unsigned int取代unsigned short。int的使用会降低程序运行的效率,特别是在数据传输带宽比较小的旧式设备上。使用BaseVertex,只要单个对象的组分不超过65536,就可以都使用unsigned short。
另一个原因是,人为的控制偏移量需要准确的控制你使用的文件。当从文件中加载索引网状数据的时候,这个数据并没有经过base vertex的偏移;它都是相对于模型开始的位置。因此在对每个对象进行存储的时候,只需要存储basevertex,而不需要对每个发生偏移的vertex都进行存储。
重叠和深度缓存
下面接着上上章的问题,为什么相对于视野更加远的物体遮挡了比较近的物体。为了回答这个问题,我们首先需要记得opengl是什么。opengl技术手册中定义的是一个基于光栅格化的渲染器。光栅话的实现方式提供了硬件实现和优化的可能,也会对程序员提供了很大的能力。但是,它们还是不够智能的。光栅器基本上就是一个三角形绘制器。顶点着色器告诉顶点的位置在哪,片段着色器提供三角形特定位置需要着色的颜色。但是不管怎么神奇,基于光栅化的绘制就是绘制三角形。
在通常情况下光栅器是非常迅速的,也能够很好的绘制三角形。
但是光栅器仅仅按照用户的告知进行绘制的。它们按照既定的顺序来绘制三角形。也就是说上述出现对象之间重叠的原因是,被重叠的对象先被绘制了。这个问题被称为隐面消除。
对于这个问题的解决,你也许最先想到的方法是,越远的物体越早绘制。也就是说先按照深度进行排序,然后先绘制深度比较大的物体。你也许会接着想到这个方法在对象数量增加的时候会变得非常不合理,特别是当三角形的数量达到百万级别的时候。
更糟糕的是,即使你不考虑深度排序的性能问题,这个方法也并不能都适用。试想下,你可以让三个三角形在放置的时候相互交叠。如下图所示:
Figure 5.2 Three Overlapping Triangle
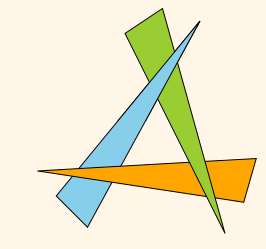
因此简单的深度排序并不能很好的解决这个问题。我们需要更好的方法。
有个方法是对每个片段都附上深度信息。如果一个片段位于更深的深度,那么在绘图的时候不去绘制这个片段。通过这样的方式,由于这个深度的比较是针对每个片段的,因此对于上述三个三角形相互重叠的情况也适用。
这个深度上的标记是窗口坐标系中的z值。从前面介绍的文章中我们已经知道z值的取值范围在[0,1]之间。0是最近,1是最远。
片段着色器中的颜色输出到了颜色图像缓存中。它通常将深度信息存储在深度缓存中,也被称为z-buffer。深度缓存是一个大小与颜色缓存一样大图像中。但每个图像的元素是浮点型数值,而不是color对应的vec4类型的数值。
和颜色缓存一样,针对窗口的深度缓存是在opengl初始化的时候自动创建的。当然opengl在初始化的时候也可以选择不创建深度缓存。freeglut能够处理opengl此类初始化。
仅仅将深度信息写入还是不够的。这个建议的想法还需要当当前片段着色器的深度在深度缓存中当前位置的深度之后的时候,需要阻止片段的写入。这个过程成为depth test。在opengl中,这个测试并不需要确定一个特别的方向;任何形式的比较都是可以的。如果测试通过了,那么片段的输出结果会写入到适当的缓存中。反之,则不会。
为了激活深度测试,需要调用glEnabel(GL_DEPTH_TEST),取消深度测试只要相应的调用glDisable即可。在测试开启之后,我们需要调用glDepghFunc来设置深度测试之间的关系。
测试函数可以是GL_ALWAYS(总是写入),GL_NEVER(都不能写入),GL_LESS,GL_GREATER, GL_LEQUAL, GL_GEQUAL, GL_EQUAL或者是GL_NOTEQUAL。这个测试函数是将即将输入的片段的深度放置与函数的左侧,深度缓存中的数值位于函数的右侧。因此,GL_LESS意味着,当待输入的片段的深度小于深度缓存中的深度的时候,就将该片段的输出写入到特定的缓存区。也就是说,近的物体会遮挡远的物体。
既然深度是片段着色器的输出值,那么在片段着色器中理应可以设置这个值的大小。确实可以,不过通常情况下是当窗口坐标系中的x,y值被计算出来之后自动计算得到的。
深度和视口
对于窗口坐标系,我们在处理深度之后还有一个问题需要处理。glViewport函数定义了标准化坐标系到窗口坐标系的转换。但是glViewport仅仅定义了xy两个维度的转换。
窗口坐标系的z值范围是在[0,1]之间的,而标准化坐标系中的范围是[-1,1]之间的。glDepthRange函数给出了两者之间的关系。这个函数有两个入参,窗口坐标系中的zNear,zFar。这个值对-1,1线性对应。
Note
不要将这里的zNear,zFar和相机坐标系中的类似的两个值搞混,两者是不同的。
带深度的渲染
关于深度检测设置相关的代码如下:
Example 5.10 Depth Buffer Setup
|
|
这些设置函数是最常用的函数,它启动了深度测试,设置了depth func为GL_LEQUAL,同时还设置了映射范围。
通常情况下使用GL_LEQUAL比GL_LESS更为常用。这样就允许我们对多通道算法的使用,使用相同的顶点着色器渲染相同的几何,但是使用不同的片段着色器。这些东西将在很后面的内容中介绍。
glDepthMask函数的调用可以将片段着色器中深度的数值写入到深度缓存中。深度检测的单独使用并不够用来写入深度的值。这允许对那些没有将深度信息写入到深度缓存的对象进行深度检测,对于颜色输出也起作用。这里我们并没有用到它,但在一些特殊的算法中可能有用。
这里还有一个问题,我们知道了片段着色器的输出会写入到深度缓存中。那么深度缓存中初始化的值是从什么地方来的呢?回想一下颜色缓存中的初始颜色是通过glClear来进行设置的,接着就很容易想到深度缓存的写入也是有这样一个类似的函数。
是的,对深度缓存初始值设定的函数也是glClear。glClearColor来定义即将被初始化的颜色,glCLearDepth来定义即将被初始化的深度值。然后在通过glCear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);完成初始值的设定。
Example 5.11 Depth Buffer Clearing
|
|
上面的代码将颜色缓存区中的值都设置成(0.0,0.0,0.0,0.0),将深度缓存中的值都设定为1.0。
这样我们得到的新的结果就是:
Figure 5.3 Depth Buffering

这样不管对象是怎么放置的,我们都能够得到理想的结果。
让我们进一步加深关于深度缓存的认识。如,想要将一个物体和另一个物体有部分重叠,那么我们只需要对z方向的偏移量进行适当的更改。
|
|
此时的结果图为:
Figure 5.4 Mild Overlap

边界和裁剪
如果你重新回顾透视投影一章,我们使用了顶点着色器执行之后能够自动处理w值的图形芯片,而不是在顶点着色器中手动的进行操作。在这里,我们将会知道为什么需要硬件自动完成该功能。
让我们来回忆一下整个的数学公式:
Equation 5.1 Perspective Computation
$$\vec{R}=\vec{P}\left(\frac{E_z}{P_z}\right)$$
其中R是透视投影之后的位置,P是相机空间中的点,E_z是透视平面在相机空间中的z值,Pz是P点在相机空间中的z值。
当看到类似上述的公式的时候,会想到一个问题,可以除以0吗?如果当相机坐标系中的点恰巧等于0的时候,该如何处理呢?也许会很容易的想到除以0,就类似与得到一个无限大或无限小的值。其实,让我们换个角度来看待这个问题。首先,我们知道w为0的时候,相机坐标系中的点的z值也是0,而根据相机坐标系中zNear的取值范围,大于1可知,0都是在显示范围之外的。既然如此,我们还需要纠结是否需要除以0这个问题吗?
裁剪是将一个三角形打碎成不同的小三角形,只有当这个小三角形在可见区域范围内才会被保留。裁剪正式发生在裁剪坐标系空间的,同时裁剪坐标系也是一个齐次坐标系系统,我们不需要忧虑除以0的事件的发生。2d的裁剪模拟类似下图:
Figure 5.6 Triangle Clipping
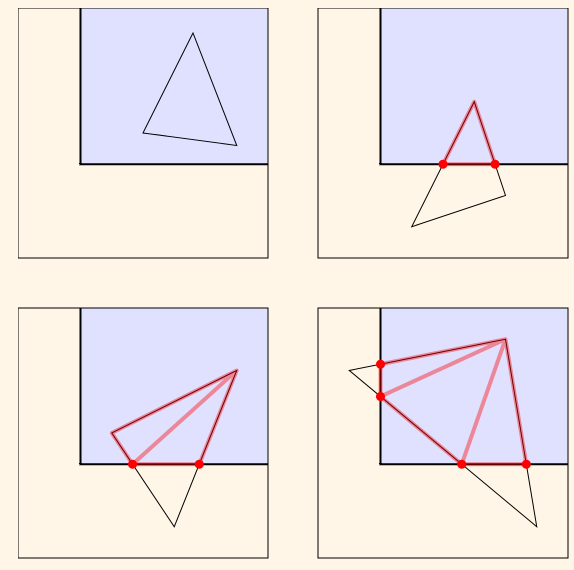
为了更好的看到实际裁剪的结果,可以运行顶点裁剪中的示例。这和深度缓存是类似的,除了对象被移到了很靠近zNear的位置。
Figure 5.7 Near Plane Clipping

深度夹紧
图5.7中的结果并不是理想的,对于一个内部没有中空的物体,我们的到了中空的效果。同时我们也没有看到这个物体的背面。
如果计算机图形是弹性入射的,那么裁剪就完全阻止了弹性入射。那么我们该如何处理这种情况呢?
最常用的方法是不允许这么做。也就是说,要了解物体在逐渐靠近近平面,同时不要让物体过分的靠近近平面。这种方式是对物体的移动进行了一定的限制。
一种更加合理的机制是depth clamping。这个是直接将相机的远近平面裁剪直接关闭。而是通过标准坐标系中的-1,1范围对深度上的显示和是否裁剪进行控制。
Eample 5.12 Depth Clamping On/Off
|
|
当你运行这一例子的时候可以看到下图:
Figure 5.8 Depth Clamping
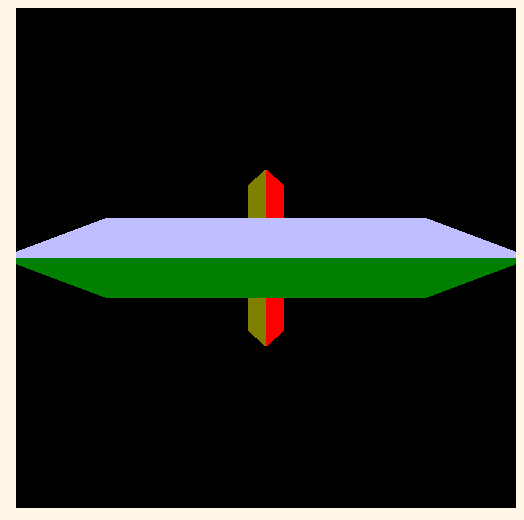
这个结果看上去是正确的,看上去我们的问题得到了解决。
那么我们将后一个对象往前面移动的时候,可以得到类似与前面出现的交叉的情况。
Figure 5.9 Depth Clamp With Overlap

此时,让我们来回顾下,什么是深度加紧,它的解释是,将比zNear更小的值,变成zNear,将比zFar更大的值变成zFar。因此,当你渲染第二个对象的时候,一些已经被加紧了的片段会被再次渲染。
因此,当渲染的物体之间有重叠的时候,就需要谨慎的使用深度加紧的策略。
总结
在这一章中,我们学习到了:
- 顶点数组对象封装了所有渲染中需要用到的对象。包括,顶点属性数组,缓存对象,和元素缓冲区。
- 基于索引的渲染,通过索引值来获取顶点数组中对应的点。索引的顺序和opengl识别的顶点的顺序是相同的。基于顶点的索可以将索引存储在缓存对象中,然后使用glDrawElements进行绘制。
- 对索引增加偏移量的方式可以访问其他的顶点,此时可以使用glDrawElementsBaseVertex。
- 可以通过深度缓存和特定的深度检测方式来对表面进行消除。
- 在相机坐标系zNear和zFar范围之外的对象会被裁剪掉。当对象很靠近相机的时候,这种方式会产生空洞。
- 只要没有重叠部分,通过深度夹紧的方式可以修复裁剪空洞,同时对象也不能超出相机坐标系中的原点。
Author grassofsky
LastMod 2017-06-16